Witness Update: Upgrade Windows Home PC Server to 128Gb RAM & 2TB RAID NVMe - preparation for Hive API Node
My witness node on WSL2 on a Windows 10 Home PC has been running for 1.5 months now and has been nicely stable.
The only outages were caused by my kids pressing buttons (now covered) and scheduled maintenance.
I have a plan to turn this machine into an API node and run the witness node on a less beefy machine.
But first it needed upgraded Storage and RAM, as Hive node performance is very dependent on these two things.
Upgrade of SSD Storage
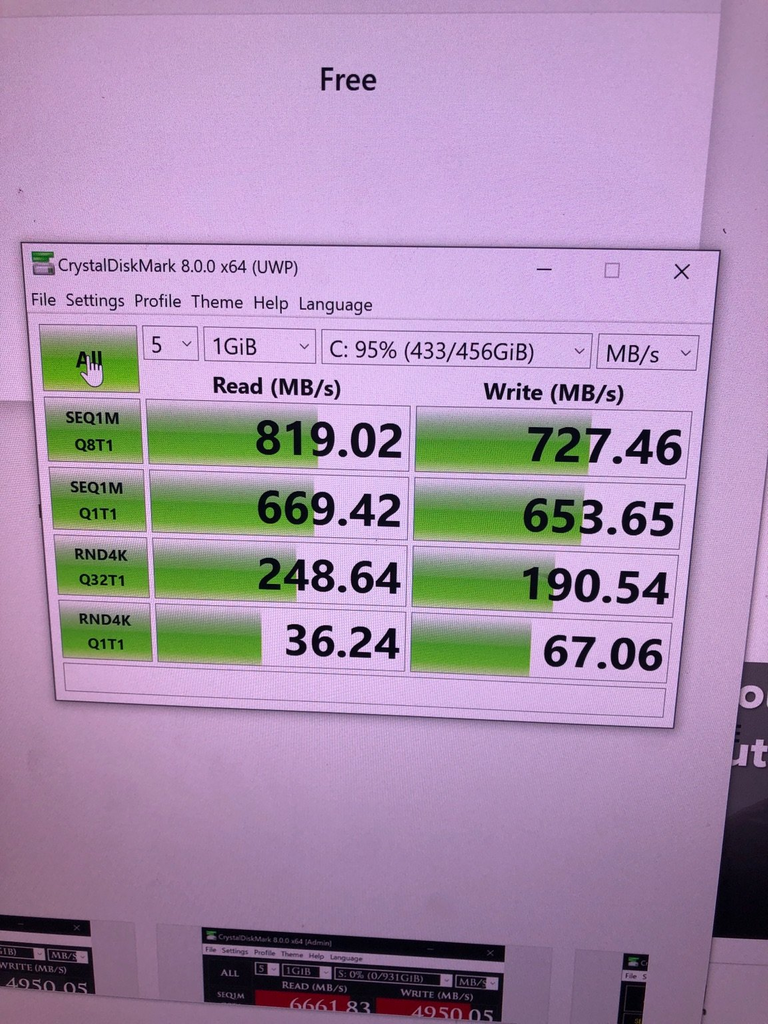
For the first 6 weeks my witness was using my 500Gb NVMe C: drive running on a Gen 2 PCIe x2 slot.
Given the blockchain is 330 Gb by itself and snapshots are about 3Gb each, I was running out of storage space fast.
Also, the Gen 2 PCIe x2 was limiting performance.
I had an Acorn Nest PCIe card that had two M.2 slots (PCIe Gen 3 x4) and a PLX switch (to allow bifurcation) lying around so I thought I'd buy two 1Tb NVMe drives and create a 2TB RAID 0 array as super fast storage for my Hive node.
Thanks to @brianoflondon I was about to get two of these babies for $105 each.

I installed them in the Acorn Nest card and plugged them into a 16x Gen 3 PCIe slot on the X99 motherboard of my Windows Home PC server.
The X99 Motherboard only supports SATA RAID so I used Windows Disk Manager to create a stripped array (AKA RAID 0).
It is software RAID but according to reports its performance is just as good as hardware RAID.
I then ran CrystalDiskMark and was blown away - Almost 5GB/s read and 4Gb/s write speeds!!
More than 5 times faster than my 500Gb NVMe C: drive.
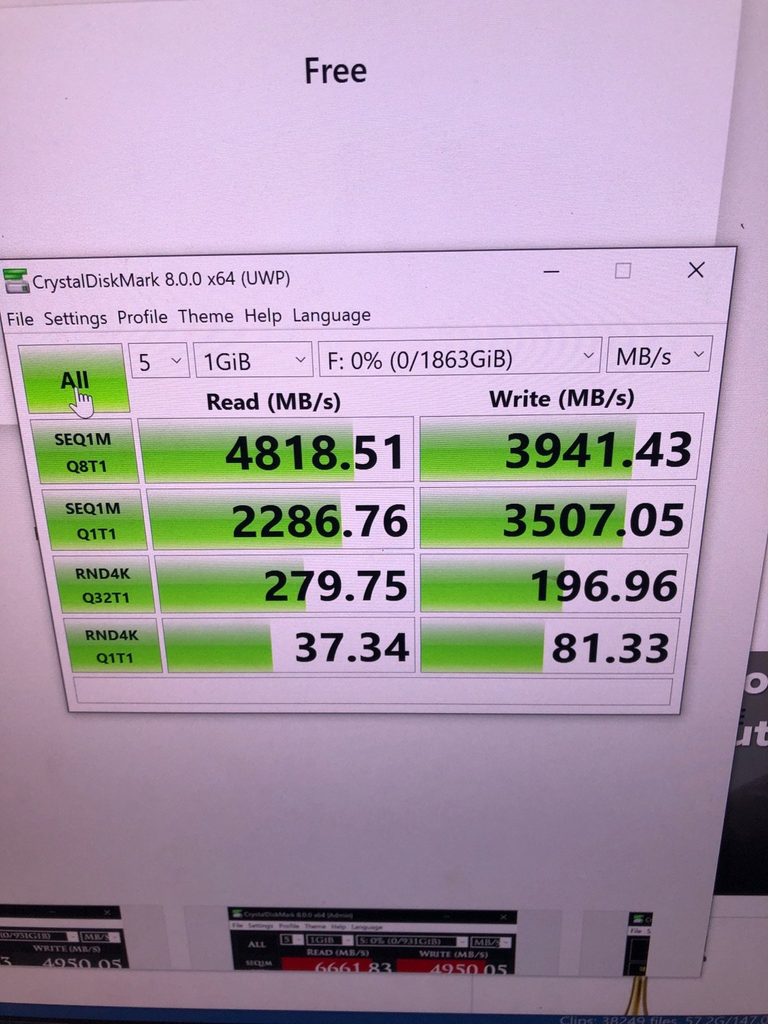
Storage hardware upgrade done
Upgrade of RAM to 128Gb
The X99 motherboard has 8 RAM slots and I had 96 GB of DDR4 DRAM in place. But I had another two 16Gb DRAM sticks of the same type, which I had been using to test other machines. I decided to put it back in to upgrade to 128 Gb RAM.
Unfortunately when I first installed it the system didn't recognise it and after an hour playing around I realised I had to take out RAM and reinstall it in a specific order for it to be all recognised.
RAM upgrade done
Moving WSL2 to new RAID 0 Array
I now had to move my WSL2 from the 500GB C: drive to the new 2TB RAID 0 F: drive.
Simple right?
NOT!
I did a lot of research on the internet to find out how to do this - you can't just move the WSL2 virtual hard disk in Windows Explorer.
I eventually worked out what seemed a quite simple process using the WSL import export process and wrote out the commands so I could check them and avoid mistakes.
F:\Shared\WSL2
cd dockerdata
wsl --export docker-desktop-data docker-desktop-data.tar
wsl --unregister docker-desktop-data
wsl --import docker-desktop-data F:\Shared\WSL2\dockerdata docker-desktop-data.tar --version 2
cd ..
cd dockerdesktop
wsl --export docker-desktop docker-desktop.tar
wsl --unregister docker-desktop
wsl --import docker-desktop F:\Shared\WSL2\dockerdesktop docker-desktop.tar --version 2
cd ..
cd Ubuntu
wsl --export Ubuntu-20.04 Ubuntu-20.04.tar
wsl --unregister Ubuntu-20.04
wsl --import Ubuntu-20.04 F:\Shared\WSL2\Ubuntu Ubuntu-20.04.tar --version 2
cd ..
The whole process should have taken less than an hour but I put off doing this until it was 11am and I had most of a day free.
Because Microsoft!
Everything went fine with the export and re-import to F: of the dockerdata and dockerdesktop.
Ubuntu exported fine.
It took about 20 min because the .tar file created was 330 Gb because it contained the Hive block_log.
Then I came to the final import.
It ran for about 15 minutes and then failed with "Unspecified Error".
How helpful of Microsoft!
I looked it up on the internet and found suggestions to import as WSL version 1 and then convert to version 2.
So I did that.
The import worked but the conversion failed with a message regarding write fail on the block_log file.
The process was using 85% of my then available 96GB RAM so I decided to do the RAM upgrade described above at this point.
I tried both direct import and WSL1 import and conversion again with more RAM. Same problem.
I tried increasing the size of the swap file. Tried both again - same problem.
I started to suspect that the problem might be related to the 256GB standard limit on WSL2 virtual hard disks.
Microsoft Fail!
Normally you can increase the maximum size of the virtual hard disk via a series of commands (instructions in my previous post).
But when importing a WSL2 distro that isn't possible because the virtual hard disk is only created as part of the import process.
But surely Microsoft would have code that checked the size of the import file and adjusted the maximum size of the virtual HD accordingly?
After all, the main reason people want to move their WSL2 distros to another disk is that they are running out of space.
But NO!
It turns out it is impossible to directly import a WSL2 distro over 256GB in size.
This is a huge Microsoft fail as WSL2 is core Windows functionality used my millions of Devs around the world.
Big distro files are common for all sorts of reasons, not just blockchains.
I devise a solution
After a lot of research I found that there was no documentation of the reason for this problem or its solution.
I was on my own. 7 hours of working on this and a witness that was down as a result and I was really frustrated.
I realised that the problem was the block_log file and noticed that after a WSL1 import it was directly accessible in a F: folder on Windows Explorer. So I decided to copy the block_log file out of WSL and into a normal Windows directory.
The process was slow but it worked.
I deleted the block_log file in the WSL directory and ran the process to convert from WSL1 to WLS2 again.
wsl --set-version Ubuntu-20.04 2
It worked!
A WSL2 virtual hard disk was created with everything except the block_log.
I then went through the process for expanding the virtual hard disk (linked above).
I then copied the block_log file back into the virtual hard disk from within Ubuntu using cp mnt/f/
But because I am not a Linux expert I made a mistake and used "/" for the destination current directory rather than "."
It all seemed to work. The virtual hard disk was 335Gb in Windows.
I loaded my latest Hive snapshot with
./run.sh loadsnap latestsnapshot2
12 minutes later I get the message that the block_log file is empty. WTF!
After checking the file size via various means I realised that maybe I copied the block_log file to the wrong place.
I go looking for it and finally find it and mv it to the right place.
I loadsnap again and it is 11:45pm and my kids will wake at 6am.
I go to bed, hoping it will finally work.
When all 3 of my little kids wake up screaming at 4am I check.
Hooray!!. My witness node is working again on the new super fast RAID Array.
12 hours of my life to do something that should have taken 1 hour if Microsoft would code properly.
Anyway I'm learning lots of skills as a Hive witness and writing this out is both cathartic and will hopefully help others.
Please vote for my Hive witness. (KeyChain or HiveSigner)
Lol this is the first time "the kids" have tampered with the blockchain.
I like how main stream sounding that is, lol children are playing on the blockchain infrastructure lol
Yes, the whole point of this is to show how we can get better decentralisation by people running Hive nodes at home (on Windows Home), rather than almost every node being dependent on a limited number of external infrastructure providers.
Just since law is your thing, have you ever considered buying .hive?
A domain name registry with a new age custom DNSSEC would be very beautiful sight to be hold.
If you haven't heard of quad 9 DNS please try to get the Hive stuff off the Cloudflare servers! (1.1.1.1)
You'll have to explain this a bit more.
Are you suggesting I buy the .hive root level domain and set up a new tech DNS server?
This sounds a lot more technical than legal and a bit beyond my technical competence.
But it sounds like a good idea. Ownership would need to be decentralised or else you'd have the same problem.
Its way beyond my technical level here too, but yes a full out domain name registry, DNS data center (our own 1.1.1.1 / cloudflare) with modern data protection standards.
The hardest part for me to grasp, is who is at the top of the domain name registry heirchy, but we need to put rights from them to .Hive just like .gov is for government websites only, .Hive would be for Hive sites only, and you ( or another trustworthy authority) could oversee the list of people (private keys) who are approved to use those domains with the .Hive registration
I had quick look into this.
It costs $185k just to apply and comes with all sorts of contractual obligations to ICANN.
I think it would increase centralisation because of the power it would give ICANN over Hive. Currently that power is diffuse.
Well you are a legit witness sir, I have always supported you and would have to say its moot if its more centralized. Thanks for actually looking into that. I have followed ICANN a bit but its so dry, is there a chance they have competition or its in a UN agency?
Thanks for your support.
I think its being transferred to the UN (which is worse than US control).
Thats depressing.🤑 hopefully they get rich enough to fix world hunger and tell us its our fault in the freed world some more...
More likely corrupt UN flunkies will line their pockets with bribes and kickbacks.
The UN is the most corrupt organisation on earth.
This is not surprising as UN postings are a reward for a lifetime of graft in many countries.
I am a active member of the Peoples Party of Canada, represented by Maxime Bernier.
My vote in the 2018 election was for Canada leaving the UN, and telling the World Bank we will be getting a lower interest rate if they are not looking to be charged by the people of Canada, for their criminal interest rates of 2% on our entire population... literally wage slaving us for 2% of our GDP.
!BEER !BRO !invest_vote 🍀
Posted using Dapplr
Thanks for the various upvotes and tips.
Allways!
!BEER 🍻
have a good one 🍀 and keep up the progress. Sounds all verry good 😆
Greez from 🇨🇭
Posted using Dapplr
View or trade
BEER.Hey @apshamilton, here is a little bit of
BEERfrom @sandymeyer for you. Enjoy it!Learn how to earn FREE BEER each day by staking your
BEER.@sandymeyer denkt du hast ein Vote durch @investinthefutur verdient!
@sandymeyer thinks you have earned a vote of @investinthefutur !
It will be a major security issue to run a public node and a witness node from the same ip. What about ddos ?
I'm not planning to have a public API node and witness node on the same IP. They will be separate computers and will have separate IP addresses.
My Server PC has two gigabit ethernet ports so could actually have separate internet connections on the one PC.
If you are talking about the IP of my main internet connection then this can be addressed with a VPN, including a router level VPN, or a secondary internet connection.
I haven't decided whether my Hive API node will be public or available only to a limited number of people / apps.
I am considering running it mainly to provide an API to a independent Hive-Engine node that will verify token balances and transactions for important Hive-Engine tokens.
I remember well that it said somewhere in the original steem repo, that the witness ip should be kept secret.
That's exactly what I mean.
Either node rerouted through VPN sounds like a major hassle and also might drop the response times significantly. I would check with some knowledgeable witnesses (perhaps in witness channel) or another sysop professional.
My guess would be: No good.
2 seperate connections would work fine, but then you are reaching a point where a datacenter (maybe a small business - for more decentralization) would be the wiser option ...
I think this curent post by @techcoderx provides the solution to running API nodes at home.
Run the API non-public facing and just run jussi on a very light weight datacenter node for $5 a month.
Sounds good.
btw I'm only trying to help - still supporting your witness.
Your comments are much appreciated.
Its good to be reminded of these things.
Thanks.
!discovery 30
This post was shared and voted inside the discord by the curators team of discovery-it
Join our community! hive-193212
Discovery-it is also a Witness, vote for us here
Delegate to us for passive income. Check our 80% fee-back Program
View or trade
BEER.Hey @apshamilton, here is a little bit of
BEERfrom @sandymeyer for you. Enjoy it!Learn how to earn FREE BEER each day by staking your
BEER.