Making a script to get updates when your voting power is 100% Part 01
Hello all
I am working on building an app that sends the user a message when their voting power is 100%
@trostparadox gave me an idea that it would be great if we could notify a user on when we have 100% voting power again. I came up with so far 2 different methods. Web-scraping and hive data.
Method 1: Web-scraping
If you are new to hive you might now be familiar with a website called hivestats. If you type in
browser
https://hivestats.io/@your-user-name
This website will display many different statistics about your account. One of these stats is your hive power.
There are many different python and javascript libraries for web-scraping. A pretty straight forward python library called beautifulsoup4 can work great. For some reason I am having an error though. But here are the basics.
In the image below you can see there are different dividers in this ginormous html code. Using beautifulsoup4 we can get the url and parse the html to have all the different html components to sort through.
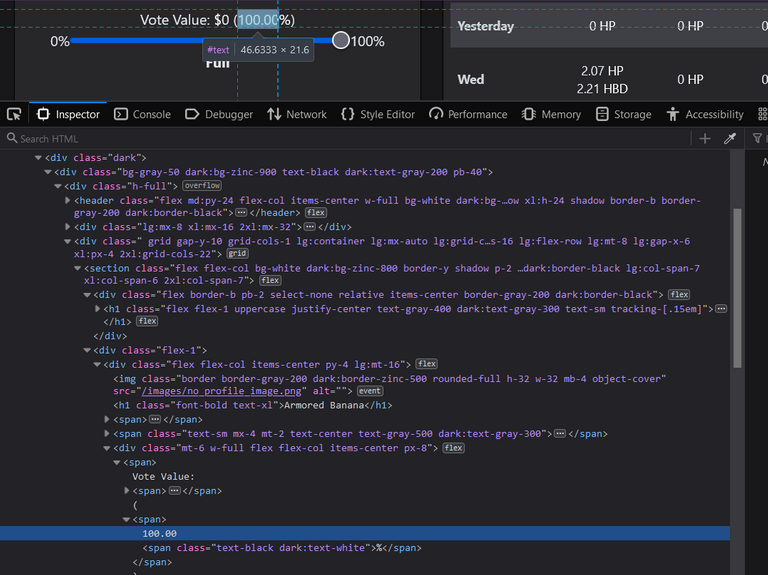
The code is something like this:
python
import requests
from bs4 import BeautifulSoup
r = requests.get("https://hivestats.io/@armoredbanana")
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.prettify())
output:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<link href="/favicon.ico" rel="icon"/>
<meta content="width=device-width,initial-scale=1" name="viewport"/>
<meta content="#000000" name="theme-color"/>
<meta content="Track, Analyze and Optimize Your Hive Account" name="description"/>
<link href="/manifest.json" rel="manifest"/>
<title>
HiveStats
</title>
<script defer="defer" src="/static/js/main.1ebe7a24.js">
</script>
<link href="/static/css/main.9cd37ad2.css" rel="stylesheet"/>
</head>
<script async="" data-skip-dnt="true" defer="defer" src="https://api.hivestats.io/latest.js">
</script>
<noscript>
<img alt="" src="https://api.hivestats.io/noscript.gif?ignore-dnt=true"/>
</noscript>
<body>
<noscript>
You need to enable JavaScript to run this app.
</noscript>
<div id="root">
</div>
<div id="spawn">
</div>
</body>
</html>
As you can see this outputs the parsed html, but it ends at the div with id spawn.
On other web pages, if you scrape them, the amount of parsed html displayed is quite more. And as you can see from the image above, our information is within this root divider, but somehow we cannot access it as of right now.
For example if you run this code
python
import requests
from bs4 import BeautifulSoup
r = requests.get("https://hivestats.io/@armoredbanana")
soup = BeautifulSoup(r.content, 'html.parser')
#print(soup.prettify())
s = soup.find('div', id = 'root')
x = s.find_all('div')
print(x)
our code outputs:
python
[]
I am looking into other methods of webscraping from javascript enabled websites
Method 2: hive blockchain data
The second method I am looking into is can I get data through the hive blockchain. Hivestats.io gets their data somehow, we just need to figure out how!
Thank you for reading and Part 2 will come soon!
Electronic-terrorism, voice to skull and neuro monitoring on Hive and Steem. You can ignore this, but your going to wish you didnt soon. This is happening whether you believe it or not. https://ecency.com/fyrstikken/@fairandbalanced/i-am-the-only-motherfucker-on-the-internet-pointing-to-a-direct-source-for-voice-to-skull-electronic-terrorism
Fortunately, voting-power replenishment follows a strict timeline. That means each time you check an account's voting power, you know exactly how long, at the earliest, the voting power will reach 100% (or whatever threshold the user wants you to check). Then, you can check back at that specific time. If no voting activity has occurred in the meantime, then the threshold will have been met and you can send the notification. If any voting activity has occurred, then you will know exactly when to check back again.
You will need to decide how soon after the notification is made (i.e. the threshold has been met) before you check back again. I suppose that could be a user-selected configuration. For instance, if the user sets that at 1 hour, then they will get a notification as soon as their VP reaches 100% and then every hour thereafter, unless and until they cast a new vote.
You might also consider tracking Resource Credits as well.
That sounds handy. Remember to tag your posts #vyb so we can give you decent upvotes!
@armoredbanana Looks like the text here on the hivestats page is added by JavaScript code.
I've tried scraping this with selenium web driver and it worked. Here's my code:
'''
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'C:\Users\bteja\Documents\geckodriver.exe') ##this is the path where my geckodriver exists
hivestats_url = 'https://hivestats.io/@bhanutejap'
driver.get(hivestats_url)
vote_value_percentage = driver.find_elements_by_xpath('/html/body/div/div/div[1]/div/div[2]/section[1]/div[2]/div/div/span[1]/span[2]')
print(vote_value_percentage[0].text)
'''
You can get the XPath by inspecting the element, right click and copy full xpath.
You may also want to check out this StackOverflow thread: https://stackoverflow.com/questions/8049520/web-scraping-javascript-page-with-python
The top suggestion in the above StackOverflow thread mentions a solution to use the dryscrape module along with BeautifulSoup, I checked for that, but looks like it is supported only on Linux/MacOS. (https://github.com/niklasb/dryscrape)
Congratulations @armoredbanana! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 50 replies.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!