Scraping job descriptions for NLP project
Motivation
Recruiters have several difficulties when trying to find the right candidates for their job positions. They can spend a lot of time trying to get the perfect match for the task, and in the path they might end up picking an "okay" candidate instead. In addition, they receive tones of applications, that are difficult to parse.
In the other hand, the job seekers tend to apply for several job positions. Partially because some of these job descriptions are not properly built to catch the right candidate, and also because there is few guidance in order to help them all through this process.
There are several platforms that have been improving their technology in order to provide good matches between job positions and job seekers. And most of this effort is being done using Natural Language Processing (NLP).

One of the ways of doing this match, is by comparing the skills on the job positions with the skills of the candidates, but the algorithm behind can be way more complex, than what it looks.
I won't cover any NLP models in this post, because there is a lot to say about Data Sourcing and Data Cleaning first.
Data Sourcing and Cleaning (with Python)
To obtain the existing jobs, I had to look for the International Standard Classification of Occupations (ISCO). Luckily, I was able to find a Kaggle dataset, with the ISCO codes (major groups, minor groups, sub major groups and unit groups).
In the end I organized a Pandas Data Frame in the following way:
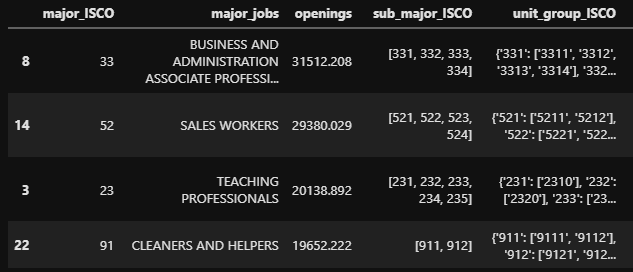
From the unit group, I was able to obtain the careers, so I had to search for a dataset or website that could provide me jobs based on the unit group. I finally found Tucareers.
Below, you can see the function I used to scrap the website (using BeautifulSoup) and return the careers:
def get_careers(dict_unit_groups):
"""Takes the dictionary of unit groups as input, and gives all the careers associated with the major group"""
if dict_unit_groups:
all_careers = []
list_unit_groups = list(dict_unit_groups.values())
for element in list_unit_groups:
for isco in element:
raw_careers= make_soup(isco).find_all(
'div',
class_='field field-name-field-careers-european-standards field-type-text-long field-label-above')
for row in raw_careers:
if row.find_all('li'):
careers = [li.text for li in row.find_all('li')]
all_careers.append(careers)
return [j for i in all_careers for j in i]
return []
df['careers_in_major'] = \
df.unit_group_ISCO.apply(get_careers)
In the end, I got a Data Frame, just like the one in Figure 2, but with an extra column for careers. Since I got a column with lists inside, I decided to "explode" it and get the rows organized by the careers.
from ast import literal_eval
df['careers_in_major'] = df['careers_in_major'].apply(literal_eval)
df = jobs.explode('careers_in_major')
Some Feature Engineering was also implemented. After checking jobs.ISCO.value_counts(), I realized there were ISCOs with very few counts, so I decided to not include them in the Data Frame. In addition I went to check the jobs one by one inside each ISCO code, and some of them were removed, basically due to the fact, that there are no job positions for them available on career search websites.
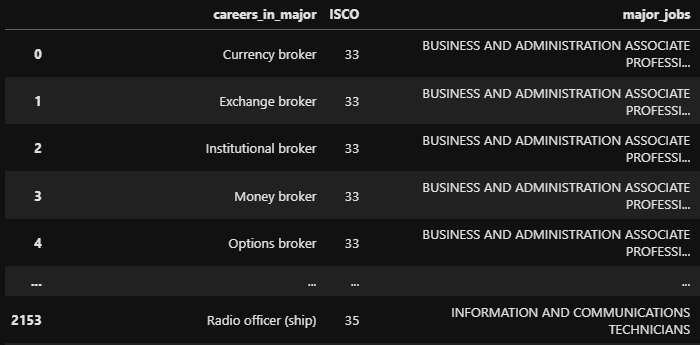
After I did some modifications to the careers column, in order to be able to scrap, such as removing ponctuation and filling the space between two words with %20. Example: nuclear%20physicist.
It was now time to scrap the job positions for each job/career. For this I used, once again Tucareers. For each job, three pages of job positions were scraped, and with it, the location and the link for the job description.
def scrap_all(career, num_pages = 3, soup = 'Tucareers'):
job_titles = []
locations = []
job_links = []
for i in range(1, num_pages + 1):
raw = make_soup(career, i).find_all('div', class_ = 'row')
career_clean = career.replace('%20', ' ')
for element in raw:
for i in element.find_all( \
'div', class_ = 'col-lg-12 col-md-12 col-sm-12'):
if career_clean in i.text.split('\n')[0].lower():
job_titles.append(i.text.split('\n')[0])
locations.append(i.text.split(' - ')[-1])
link = str(i).split('href="')
link = link[1].split('" target=')
job_links.append(link[0])
job_titles = [i.split(' – ')[0] for i in job_titles]
job_titles = [i.split(' - ')[0] for i in job_titles]
return job_titles, locations, job_links
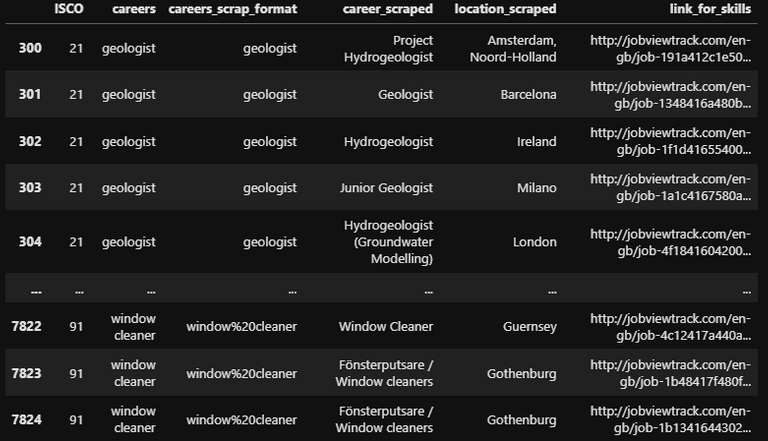
The final step to finally get the job descriptions, was to scrap the links found in the Data Frame above (Figure 4). But here was where the real problems appeared.
Proxy Rotation and VPN
After scraping a few hundreds of rows, I got blocked by the website. So I had to figure out a way to continue the scraping. First I tried proxy rotation, by trying several lists of free IPs:
working_european_proxies = []
for i in proxies_european:
print(i)
proxies = {
'http': 'http://' + i,
'https': 'http://' + i
}
try:
response = requests.get(url, proxies = proxies, timeout = 3)
print(response.status_code)
print(i, '- working')
working_european_proxies.append(i)
except:
print('not working')
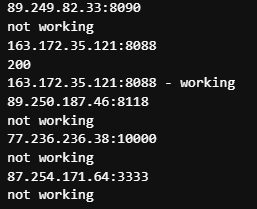
This way of tackling the problem, actually worked, the only issue was the time, I was taking 1h 30min to scrap 100 rows.
Since I didn't have that much time, I tried a different approach, which was by using a VPN. In the end, this worked much better, but I was changing the IP every 250 rows. Find below the function to scrap the links:
def scrap_link(url):
info = []
raw = make_soup(url).find_all('section', class_= 'content')
#print(f"soup: {url}")
for element in raw:
if element.find_all('ul'):
for topic in element.find_all('ul'):
info.append(topic.text)
else:
return None
return info
The final Data Frame
After manually changing the IPs for each 250 rows, I finally finished the scraping having a dataset with almost 6000 rows.
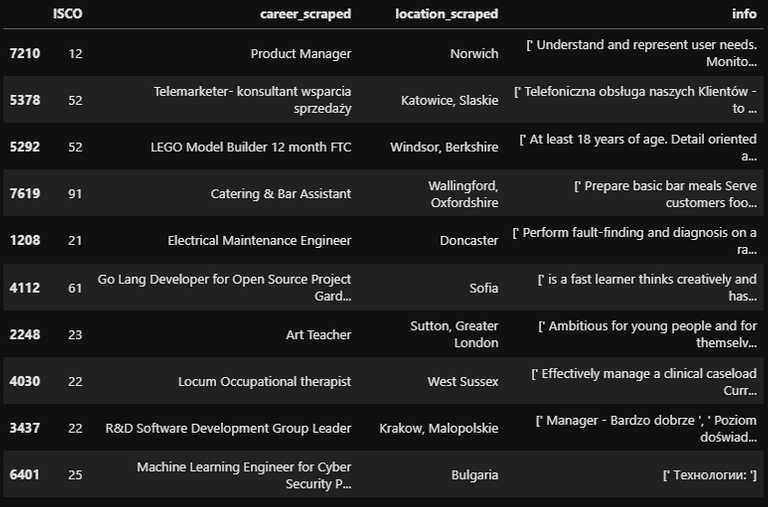
See below an example of job description:
"[' Minimum of three years experience in Python Software Development + experience with Python web frameworks Experience with API integration will be highly advantageous Experience with Tenable, Kryptowire, Netsparker is advantageous Banking/financial services background is preferred (not essential) Good understanding of Agile and DevOps cultures ', ' Create and maintain the Rest APIs Migrate the application to the cloud Dockerize and orchestrate the applications Maintain the codebase for the application. Setup end to end data processing pipelines. ']"
The next step will be to perform more cleaning and then start by trying different NLP models, such as: Word2Vec, Doc2Vec, ADL.