Explained: the Internet outage of 30 August 2020

In the early hours of 30 August 2020, internet users all over the US and Europe got a rude awakening as their connectivity stopped working: all of a sudden sites such as Discord, Hulu, Feedly, Xbox Live, and dozens of others appeared to be offline. Even major platforms like YouTube, Twitter and Google were among the impacted services, while others like Duck Duck Go and Bing Search were still reachable, albeit in an intermittent fashion.
The issues started arising with reports of failing Internet connectivity quickly ramping up. Users affected would not be able to reach websites, use email, stream movies, or gaming online.
While network operators were scrambling to understand the problem and users where setting customer service phone lines and social media accounts on fire, a trend clearly emerged - the issue was not limited to a single country nor one internet provider, but it had a much broader impact: it was, in fact, a widespread network outage.
To understand the nature of these events, one must know that "the internet" as it is commonly defined is just a general term that describes a bigger entity. Due to its nature, the internet is a network of interconnected networks, which in turn are composed of other networks in a hierarchy. An in-depth explanation of how this works would require an understanding of technical concepts like peering and transit, which is out of the scope of this post; the following description is therefore extremely simplified on purpose.
Internet Service Providers that are selling connectivity to households and companies through their subscription plans are just the last link of a long chain; climbing up in the hierarchy, ISPs are interconnected between them to compensate data flows and traffic peaks and provide redundancy in case of technical failure.
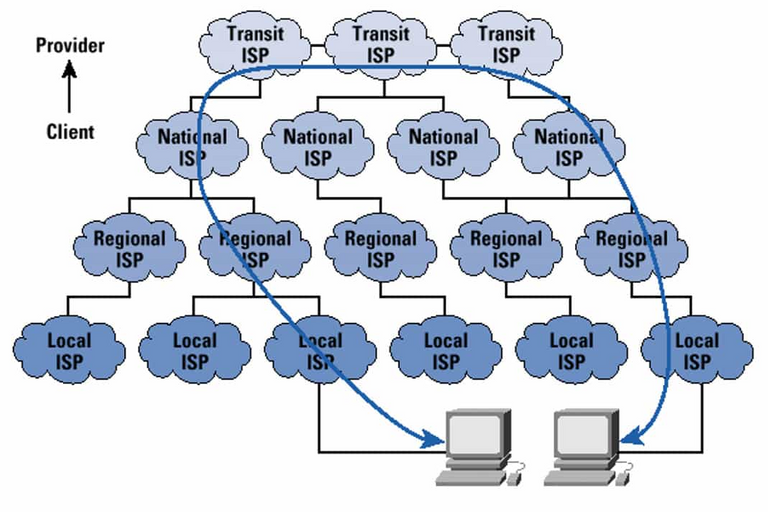
At the same time, all ISPs obtain their connectivity from higher-level providers, called Transit ISPs, who are connected to the actual backbone at the highest level - the Internet Exchange. Internet Exchange Points (IXPs) represent the larger interconnection entities among all Transit ISPs; Transit ISPs are selling their access to Service Providers who, in turn, resell it to customers and businesses. All these entities are interconnected with multiple links to provide redundancy; in case of an accident (such as a software bug, infrastructural failure or natural disaster), if one link is lost, the whole infrastructure will route traffic around the defective node and maintain its operational state.
One of these Tier-1 operators is Centurylink.
CenturyLink is one of the primary connectivity links for the infrastructure company Cloudflare, which provides Content Delivery Network services, DDoS mitigation, Internet security, and distributed domain-name-server services on a worldwide scale.
"Cloudflare has a capacity of over 42 Tbps and spans more than 200 cities in 100 countries. Our network allows us to be within 100ms of 95% of the Internet-connected population globally."
(source: Cloudflare)
Due to its wide footprint, Cloudflare operations represent a major channel for internet traffic around the world.
On 30 August 2020 around 12:10 CEST (11:10 UTC), a technical issue caused by network routing misconfiguration in the Tier-1 infrastructure of the American transit provider Level3 (acquired by CenturyLink in 2017) started causing 5xx class HTTP errors, such as HTTP 522, 502, 503.
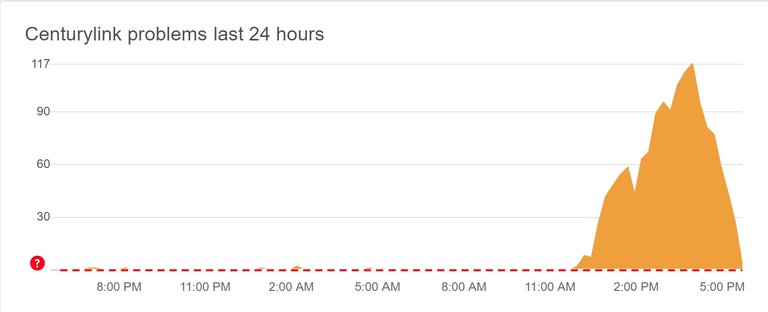
(source: DownDetector; time is CEST)
Due to these errors, all Cloudflare data centers that make use of Level3 started experiencing loss of connectivity. However, as Level3 operates as Transit provider, the issue quickly propagated across the network and, like a tidal wave, affected some of the major Internet Service providers. Only half an hour later, multiple ISPs between the United States and Europe suffered connectivity issues on a global scale.
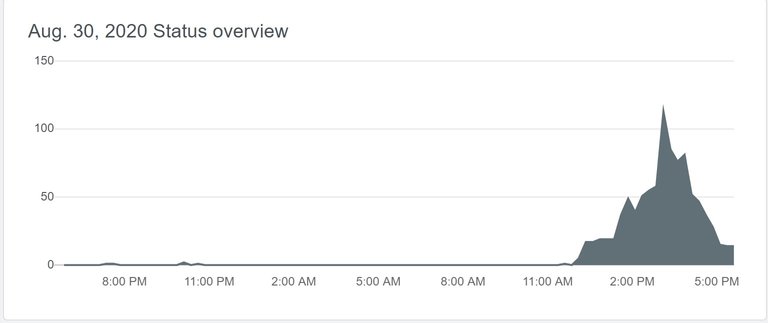
(source: DownDetector; time is CEST)
Around 10:21 UTC, Cloudflare confirmed to be aware of an issue impacting multiple customers. At 10:45 UTC, Cloudflare noticed the increased number of HTTP errors and, at 11:57 UTC, confirmed to have identified the source as an issue with one of their transit providers (later confirmed to be Level3). Corrective actions were deployed in data centers to mitigate the issue and at 15:05 UTC Cloudflare reported that, as the major provider that was experiencing issues had implemented a fix in their network, other global network providers had started to re-enable their peering sessions with it. Ten minutes later, network stability and reachability were observed to return to normal levels, and eventually the incident was declared resolved at 16:12 UTC (17:12 CEST).
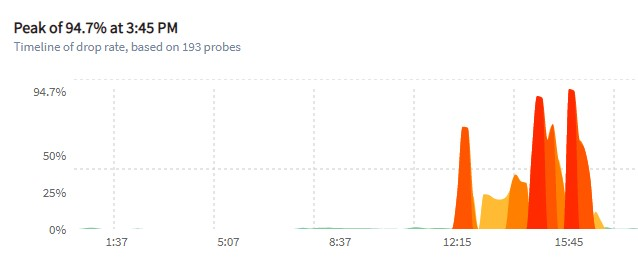
(development of CenturyLink dropped connections during the outage. Source: Fing)
“Today we saw a widespread Internet outage online that impacted many multiple providers,” a Cloudflare representative said in an email to The Verge. “This was not a Cloudflare-specific outage. Level 3/CenturyLink was responsible for an outage that affected many Internet services, including Cloudflare. Cloudflare’s automated systems detected the problem and routed around them, but the extent of the problem required manual intervention as well.”
The entire incident lasted a little longer than 5 hours, which is a remarkable time span for an event of this kind. Outages are not infrequent but, due to the network robustness and reliability, they typically last only a few minutes and have little to no impact on services and end-users. Today's event however happened at a high level in the network hierarchy, and that caused a widespread effect that spanned multiple countries across two continents.
UPDATE 31/08/2020: To give some context to the severity of the event, according to the official reports this single outage has caused a 3.5% drop in global internet web traffic. While this post is centered on one of the most affected providers, in the aftermath of the event the impact resulted very different depending on the provider and their relationship with the affected transit; many regions worldwide have not experienced any issue and some others have been being seriously disrupted. For instance:
– Cox, 56% of Arizona for 2h46m (peak 100% drop rate)
– Cox, 31.2% of Nevada for 1h20m (peak 100% drop rate)
– Frontier, 5.4% of California for 4h15m (peak 100% drop rate)
– CenturyLink, 15.7% of Colorado for 4h35m (peak 94.7% drop rate)
– HiNet, 33.6% of Taiwan for 20 minutes (peak 56% drop rate)
(source: https://app.fing.com/internet/outages/top-report)
For a more technical in-depth, Cloudflare has posted an official analysis of the incident on their blog.
Outstanding job with this post, outstanding @lucabarbera!
Thanks @fijimermaid! I'm glad you liked it.
Ohh that was some serious network and connectivity issue.
Yet handled in 5hours is some wmgood work shown by the conerned authorities.
A bad incident but it made them aware that such issues can happen and they found out the way to deal this.
This kind of issues actually happen more often than one might think, but most of them are neutralized by the infrastructure and the remaining few are handled in a timely fashion, so the general public is never affected.
wow, craziness! I can imagine a lot of folks were getting really panicked with the internet down. Nice summary, thanks!
I had some time scheduled to write when it happened, I ended up writing about the incident that prevented me to work 😅
Congratulations @lucabarbera! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board And compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @hivebuzz: