Recent Parallel Processing Computer System Technology
Note
This is one of my Doctoral assignment from Current Science and Technology in Japan Course which has never been published anywhere and I, as the author and copyright holder, license this assignment customized CC-BY-SA where anyone can share, copy, republish, and sell on condition to state my name as the author and notify that the original and open version available here.
Pipelining for microprocessor
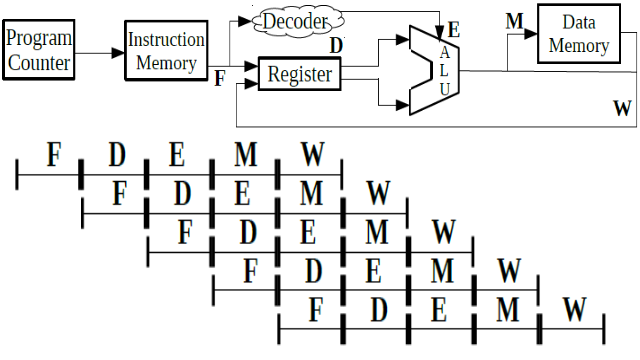
A microprocessor is an electronic component that is used by a computer to do its work. It is a central processing unit (CPU) on a single integrated circuit (IC) chip containing millions of very small components including transistors, resistors, and diodes that work together [1]. The traditional microprocessor is too simple, but it is good to be explained in the class. The traditional one have five instructions which in order are fetch, decode, execute, memory, and write. In Figure 1 is seen that the program counter accesses the instruction memory, then the register fetch the instruction, next the instruction is decoded by the decoder, later it is sent to the arithmetic logic unit (ALU) and execute the instruction, finally the result is stored in the data memory and written into the register [2].

Figure 1. Simple Microprocessor Diagram
Pipelining is a technique to speed up the processing. Without pipelining the processor will have to wait until the whole 5 steps finishes before it can execute a new one, in other words serial processing. However pipelining allows the processor to start processing the next instruction without waiting until the previous instruction processing is finished, in other words parallel processing. Figure 2 showed the simplest illustration, but the technique have grown vast, for examples there are parallel operation, superscalar, super pipelining, and very long instruction word (VLIW). There are also data dependency problems such as flow, control, anti, intput, and output that prevents performance improvement. There are some techniques such as data forwarding, and dynamic code scheduling. [3]
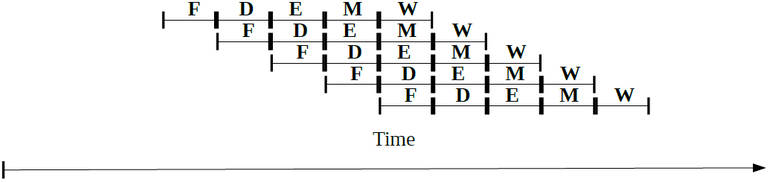
Figure 2. Simple Pipelining Illustration
GPGPU and CUDA
GPGPU was originally graphic processing unit (GPU) which is to process graphics, whether they are 2D (dimension) or 3D, still picture or moving picture (movie), and there are also animations and games, not to forget that the monitor is refreshing around sixty times a second. Just to process a single graphic took a lot of math or algorithms which is very heavy for the CPU which is why back then engineers created GPU solely to handle graphics. Today an innovation was made that GPU can be used for general purpose, and now comes the term general purpose graphic processing unit (GPGPU). [4]
Respectively the current intel i7 processor have 4 processing units (cores) while a GPGPU can have hundreds of cores, the current Geforce GTX 1080 Ti have 3584 cores. Figure 3 showed an illustration of CPU versus GPU. The essence of GPGPU is parallel processing (most people agree back when it was a GPU, it was used to parallel process the pixels in graphics). Nvidia created CUDA which is a parallel computing platform and programming model that allows to utilize their GPUs into GPGPUs. The simplest example is performing a loop program for example a hundred loops. In a CPU the loops is processed in serial order from one to a hundred, while in GPGPU the hundred loops are processed in an instant (depending on the number of cores). The processing speed greatly increases, I have example codes in C, C++, python, octave, and R which compares running in CPU and GPGPU using CUDA and OpenACC [5]. However GPGPU can only run non-specialized processes, which why CPU is still needed. The theory is long, but simply the process is first defined in the CPU, then the CPU divides the process to the cores in GPGPU, lastly the GPGPU returns the result to the CPU.
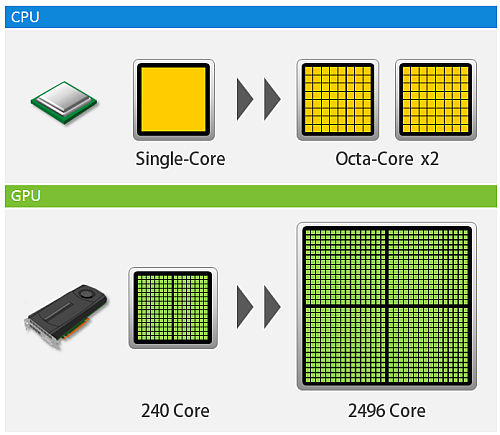
Figure 3. Illustration of CPU vs GPU (courtesy of http://www.hpc.co.jp/gpu_solution.html)
Open MP
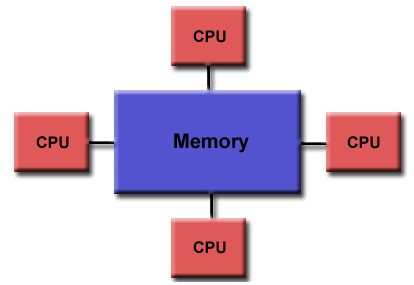
Figure 4. Shared memory [6]
Openmp stands for open multiple-processing, it is an application program interface (API) that provided parallelism in shared memory through the implementation of multi-threading. Since it is in shared memory, openmp is only utilizable on multi-core CPUs, where shared memory is a certain space on the memory to be shared by other cores on the CPU. The other keyword is thread, where it is the smallest unit of a process which can be scheduled. A process can be single thread or multi-thread. Openmp allows the threads to run in parallel speeding the process and optimizing the use of resources. The core elements of OpenMP are the constructs for thread creation, workload distribution (work sharing), data-environment management, thread synchronization, user-level runtime routines and environment variables. Openmp supports C, C++, and fortran. Back on my coding in openacc [5], the pragma directive “acc” can be changed to “omp” to use openmp in the code. [6]
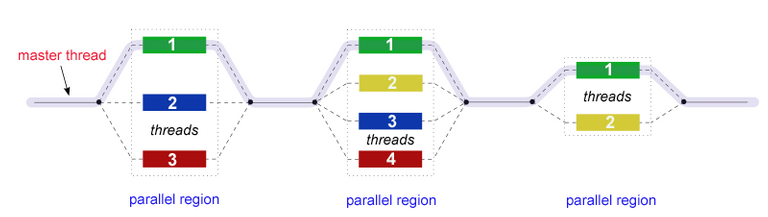
Figure 5. Parallel thread illustration [6]
Open CL
Opencl stands for open computing language. Although mostly today people elevate it for its parallelism, opencl is not just parallelism but an open standard computing language which supports heterogeneous or many kinds of systems such as CPUs, GPUs, digital signal processors (DSPs), mobiles, and even FPGAs. There are many more devices that it supports, unlike CUDA which only supports Nvidia devices. Although CUDA is great for personal projects because it has more libraries and better programming interface, but if the product is to be commercialized, then opencl is preferable because it supports many devices. Also if purely want to make the code as open as possible, opencl is best because of its compatibility. The code that was made can be portable to all sort of devices. The coding of opencl is based on C99, but today it also supports C++11. The concept parallelism is almost the same as CUDA, openmp, and openacc. [7]
Reference
- https://simple.wikipedia.org/wiki/Microprocessor
- Pipelining in a Processor - Georgia Tech - HPCA: Part 1, https://www.youtube.com/watch?v=eVRdfl4zxfI
- K. Morihiro, “Recent Computer System Technology”, Presentation Slide for Current Science and Technology in Japan Course.
- Introduction to GPGPU - General Purpose Computing on GPUs, https://www.youtube.com/watch?v=xKxG0fSymKc
- https://github.com/0fajarpurnama0/Programming-Practice/tree/master/cuda
- https://computing.llnl.gov/tutorials/openMP/
- Introduction to OpenCL, https://www.youtube.com/playlist?list=PLiwt1iVUib9s6vyEqdpcgAq7NBRlp9mAY
Mirrors
- https://www.publish0x.com/fajar-purnama-academics/recent-parallel-processing-computer-system-technology-xxwndpx?a=4oeEw0Yb0B&tid=hive
- https://0darkking0.blogspot.com/2021/03/recent-parallel-processing-computer.html
- https://0fajarpurnama0.medium.com/recent-parallel-processing-computer-system-technology-82bdbaaa94c
- https://0fajarpurnama0.github.io/doctoral/2020/07/28/recent-parallel-processing-computer-system-technology
- https://hicc.cs.kumamoto-u.ac.jp/~fajar/doctoral/recent-parallel-processing-computer-system-technology
- https://0fajarpurnama0.wixsite.com/0fajarpurnama0/post/recent-parallel-processing-computer-system-technology
- http://0fajarpurnama0.weebly.com/blog/recent-parallel-processing-computer-system-technology
- https://0fajarpurnama0.cloudaccess.host/index.php/9-fajar-purnama-academics/220-recent-parallel-processing-computer-system-technology
- https://read.cash/@FajarPurnama/recent-parallel-processing-computer-system-technology-ccd7d9a9
- https://www.uptrennd.com/post-detail/recent-parallel-processing-computer-system-technology~ODc0Nzc2