The World Of Amino Acids And Proteins #4
Hello, dear readers. Thanks for all your
supports, comments and upvotes. Today, still on my series: The World of Amino
Acids and Proteins, I’ll be discussing extensively on DNA, its structure,
modelling and its role in protein synthesis and genetic mutations.
DNA AND ITS ROLE IN PROTEIN SYNTHESIS
Deoxyribonucleic acid (DNA) is found in almost all living things. It carries genetic information that can be passed from one generation to the next. But what exactly does DNA do? It carries information to synthesize our body’s proteins from our enzymes to our skin and hair.
THE STRUCTURE OF DNA
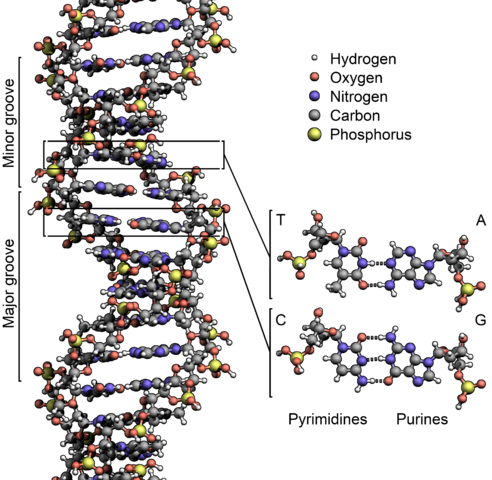
DNA is a polymer made up from monomers called nucleotides. The nucleotides have three components: deoxyribose (a sugar), phosphate and one of four bases.

We can see how a strand of DNA is formed in the figure below. Because water molecules are lost when the sugar, phosphate and base react to form DNA, this is known as a condensation polymerization.
In 1953 two scientists, Francis Crick and James Watson, working at Cambridge University realized that DNA forms a double strand, held together by hydrogen bonding between A and T and between C and G.
MODELLING DNA
A fascination for discovering the structure of DNA started, for James Watson (an American biologist), after he saw an X-ray diffraction photograph of the molecule in 1951, while researching in a Copenhagen laboratory. James Watson realized that if DNA had a diffraction pattern then perhaps the structure of genes could be worked out. He switched his research to the Cavendish Laboratory in Cambridge, where much work was being carried out on determining the structure of large molecules. Here he met Francis Crick, a British physicist. They hit it off immediately and became great friends, sharing a passion for discovering DNA’s structure; yet it is interesting to note that neither had a brief to do any research related to DNA, in fact neither actually did any direct research on the DNA molecule. They made models of what they thought DNA’s structure might be, based on observations and information from other scientists.
They already knew that:
- DNA was made up of monomers called nucleotides.
- Nucleotides are made up from a sugar, a phosphate and a base.
- There are four different bases in a DNA molecule: adenine, thymine, guanine and cytosine.
- There are always the same number of adenine bases as there are thymine bases.
- There are always the same number of guanine bases as there are cytosine bases.
- The basic structure was probably based on a helix.
Crucial to the discovery of the now accepted model of DNA was the work of Maurice Wilkins (British chemist) and Rosalind Franklin (British chemist) at Kings College London. They took an experimental approach, using X-ray diffraction images, largely taken by Franklin. In 1951, Watson attended a lecture given by Franklin, where she showed some of her superb X-ray photographs. Franklin had already used her diffraction patterns to work out the basic dimensions of the DNA strands and had realized that the phosphate groups must be on the outside of the strands in what was probably a helical structure. Because Watson took no notes of the lecture his recollection was hazy; however, Crick was friendly with Wilkins, who showed him some of Franklin’s photographs. Watson and Crick made a model based on Franklin’s results and Watson’s recollections of her lecture. But when Franklin saw it she told them that it must be wrong. She pointed out that the phosphate-sugar backbone must be on the outside of any DNA model, because only in that way could DNA interact with water, since the backbone was hydrophilic (water-loving).
Linus Pauling, the great American scientist proposed a triple-helix model for DNA early in 1953 but when Watson saw his research paper, which was never published, he knew it did not fit the data. This stimulated them to go back to making yet another model of DNA. Without Franklin’s knowledge, another X-ray photograph was shared with Crick and Watson. It was then that they realized that DNA must be a double helix, which resembled a spiral staircase – the steps being the paired bases. They started to make their ball-and-stick model, which eventually reached two metres tall. They were uncertain as to how the bases paired up in their staircase structure until a colleague pointed out that A must go with T, and C with G.
They finished their model and published their paper in Nature in April 1953. Because it so readily fitted the facts, the scientific community immediately accepted the structure. Watson and Crick received a Nobel Prize together with Wilkins, in 1962. Rosalind Franklin died in 1958 from cancer. Nobel prizes are awarded only to living recipients so she did not receive one. There are two tragedies here: the first is that Rosalind Franklin’s work with X-rays almost certainly caused her cancer; and second, her role in the discovery of DNA, though crucial, was not rewarded with a Nobel Prize. However, her achievements as a brilliant experimental scientist are now fully recognized.
{kind=link}
PROTEIN SYNTHESIS AND RNA
The code for synthesizing proteins is carried by the sequence of base pairs on the inside of the double helix. Although DNA may carry this genetic coding, DNA itself is not directly involved in protein synthesis. That is the function of another set of molecules called ribonucleic acid, or RNA.
RNA has a structure very similar to DNA, except that the sugar in the sugar-phosphate backbone is ribose (instead of deoxyribose) and thymine is replaced by uracil.
Messenger RNA
The molecule that takes the code for the amino acid sequence of a protein to the site where the amino acids are assembled to make a protein is called messenger RNA (mRNA). Each protein has a different mRNA molecule. These molecules are made by the sequence of bases on the DNA called a gene. The DNA unzips, revealing its bases, and this sequence is transcribed onto the RNA in a process called transcription. The base A on a strand of DNA will produce a U on the messenger RNA and T will produce an A.
Codons
Each amino acid in a protein is determined by a sequence of three bases. This is called the triplet code. Each triplet is called a codon. The codons tell the cell which amino acids to assemble into a protein chain. Sometimes more than one codon can code for an amino acid. For example the amino acid serine has six possible codons: UCU, UCC, UCA, UCG, AGU and AGC, but the amino acid tryptophan has only one codon: UGG.
Some codons will tell a cell to stop making the protein chain any longer. An example is UAA.
Ribosomes and transfer RNA (tRNA)
The messenger RNA carries the code to make a protein from the DNA in the nucleus of the cell to a structure in the cell called a ribosome. The ribosome provides the site where amino acids are assembled into proteins. Transfer RNA (tRNA) is the molecule that selects the correct amino acids to make up protein chain.
Just as the bases on mRNA recognize and pair with bases on DNA, so the same thing happens with tRNA. The three bases that recognize the bases in a codon on messenger RNA are called an anti-codon.
This tRNA molecule bonds to serine, the amino acid coded for by AGC in the codon on mRNA. Serine is then assembled into the protein chain in the ribosome. The ribosome travels down the mRNA chain like a bead on a necklace. Each tRNA codes for a particular amino acid. Sometimes more than one tRNA will code for the same amino acid. The tRNA brings the appropriate amino acid to the front of the ribosome, and the protein chain grows out of the back.
When production of a particular protein is sufficient for a cell’s needs the mRNA is destroyed. The permanent record is still stored in the DNA ready to make more mRNA when the need arises. The tRNA remains in the cytoplasm of the cell bringing up amino acids to make the different proteins as required.
GENETIC MUTATIONS
Sometimes the DNA sequence can become slightly muddled. This causes a mutation. An incurable disease caused by a genetic mutation is sickle cell anaemia. It affects millions of people in tropical Africa and people of African descent around the world. A tiny defect in the protein haemoglobin causes it to be shaped differently, misshaping red blood cells. These red blood cells become stuck in narrow blood vessels called capillaries, causing blockages, severe pain, and damage to the kidneys, lungs and liver. The red blood cells also have a shorter life span causing anaemia. The fault is a very simple one; a T replaces an A in the gene for haemoglobin, causing it to have a characteristic sickle shape. Now that the cause of this mutation is known there is the very real possibility of repairing this gene sequence and promising research is underway.
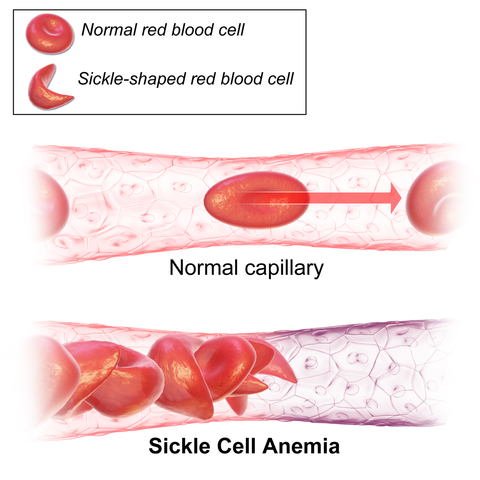
Sickle cell anaemia. BruceBlaus, CC BY-SA 4.0
{kind=link}
Sometimes mutations in the DNA structure can lead to beneficial modification to the primary structure of proteins, causing them to have a different structure and perhaps a different function. It may be that the protein that confers colour to a butterfly’s wings changes, making it more difficult for the butterfly to be seen by predators so it survives and passes on this mutation to the next generation. Perhaps haemoglobin structure is altered in such a way that allows the molecule to transport more oxygen around the body making an individual better at endurance activities such as running long distances. The primary structure of an enzyme may be altered so that the active site becomes differently shaped, giving the enzyme a different function.
Studies show that in about 5-14 per cent of the European population there is a base pair missing on a particular gene. This has an effect on the shape of the protein coating of particular cells that are susceptible to entry by the HIV virus. Through this change of shape a receptor site that the HIV virus uses to gain entry is missing, making the individual more resistant to the onset of AIDS.
SUMMARY
After reading all my previous series on The World of Amino Acids and Proteins 1, 2, 3, and this, we should be able to understand all the following concepts:
- Amino acids have two functional groups: COOH and NH2.
- Naturally occurring α-amino acids have the general formula H2N – RCH – CO2H.
- Optical isomerism occurs when two molecules, called enantiomers, exist as non-superimposable mirror images of each other. These molecules are said to be chiral.
- A carbon atom bonded to four different groups is called a chiral carbon. Such carbon atoms give rise to optical isomers.
- A pair of enantiomers rotates plane-polarized light in equal but opposite directions.
- Pharmaceutical companies often require drugs to be made up of one optical isomer (enantiomer) to avoid unpleasant side-effects. Chemicals synthesized in the laboratory usually contain a mixture of optical isomers, whereas chemicals synthesized using enzymes or bacteria often contain a single optical isomer.
- A zwitterion is formed when a COOH group donates a proton to an NH2, group on the same molecule, to give an ion that is both positively and negatively charged.
- CO-NH is called a peptide group or peptide link when it joins two amino acids together.
- Polypeptides are long-chain molecules that contain many amino acids joined by peptide links. Proteins are very large molecules that have Mr values of from 5000 to several million.
- The primary structure of a protein (either an α-helix of a β-pleated sheet) is the sequence of its constituent amino acids. It forms the protein backbone.
- The secondary structure of a protein (either an α-helix or a β-pleated sheet) is held together by hydrogen bonding between C=O and N-H in different peptide groups.
- The tertiary structure is the overall three-dimensional shape of a polypeptide in a protein. It is the result of the secondary structure folding and bending.
- Enzymes are biomolecule catalysts and nearly all are proteins. They have a very high activity and usually a high specificity. They are also very sensitive to changes in pH and temperature.
- Enzymes have a three-dimensional active site to which substrate molecules can bind. This lowers the activation energy for a particular reaction. Some molecules can act as enzyme inhibitors occupying the enzyme’s active site.
- DNA is a condensation polymer made up of monomers called nucleotides. These nucleotides are themselves made up of deoxyribose, phosphate and one of four bases: A, T, C or G.
- DNA exists as a double helix and other models were put forward before the currently accepted version produced by Crick and Watson. Bases pair in the double helix A to T and C to G. These pairings are held together by hydrogen bonds.
- Messenger RNA (mRNA) lines up with bases on DNA to transcribe the information required for protein synthesis. A sequence of three bases is required to code for a particular amino acid. This triplet code is called a codon.
- Transfer RNA (tRNA) contains three bases that line up with the codon; these three bases are called an anti-codon. Each tRNA is also bonded to a specific amino acid.
- The ribosome travels down mRNA and is the site of protein synthesis. tRNA molecules bring their amino acids to be bonded into a growing protein chain.
- Changes to the base pairs in DNA, called mutations, can give rise to genetic diseases such as sickle cell anaemia. However, modification to base pairs may alter the primary structure of proteins in a beneficial way, altering structure and/or function.
REFERENCES
http://faculty.ccbcmd.edu/courses/bio141/lecguide/unit2/control/function_of_DNA.html
http://homepage.smc.edu/wissmann_paul/anatomylabmanual/transcription&translationhandout.pdf
https://en.wikipedia.org/wiki/DNA
https://www.livescience.com/37247-dna.html
https://www.teachermagazine.com.au/articles/modelling-the-molecule-of-life
https://en.wikipedia.org/wiki/Molecular_models_of_DNA
https://www.thoughtco.com/dna-models-373331
https://en.wikipedia.org/wiki/RNA
https://www.ncbi.nlm.nih.gov/books/NBK21603/
https://en.wikipedia.org/wiki/Messenger_RNA
https://www.nature.com/scitable/definition/codon-155
https://en.wikipedia.org/wiki/Genetic_code
https://en.wikipedia.org/wiki/Transfer_RNA
https://www.nature.com/scitable/definition/trna-transfer-rna-256
https://en.wikipedia.org/wiki/Mutation
https://ghr.nlm.nih.gov/primer/mutationsanddisorders/genemutation
Congratulations @empressteemah! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
Thanks
This post has been voted on by the SteemSTEM curation team and voting trail. It is elligible for support from @curie.
If you appreciate the work we are doing, then consider supporting our witness stem.witness. Additional witness support to the curie witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Thanks for having added @steemstem as a beneficiary to your post. This granted you a stronger support from SteemSTEM.
Thanks for having used the steemstem.io app. You got a stronger support!