Introduction to Virology / Introduzione alla Virologia
Virus
Hello all friends, today in this new column we will go to make an introduction on Virology, we will begin to see what are the Viruses, how they are classified, how they act and how they work at biological/molecular level, how they replicate and much more, good reading.
Introduction
Viruses can be defined as organisms because they contain genome.
An organism, however, is usually defined as something composed of a single cell (unicellular) or multiple cells (multicellular) while viruses are acellular organisms.
In addition to the genome, the virus contains structures that allow it to protect itself from the external environment and to replicate within the cell that hosts it, so they are considered as obligatory intracellular parasites.
The cell that will be infected will do all the activities necessary to replicate the organism instead of the virus.
The virus has an abnormal replication, in fact a single viral particle (called virion) infecting a single cell within a single replication cycle can give rise to thousands of viral particles daughters.
Therefore, in this apparently simple structure is inherent a great efficiency.
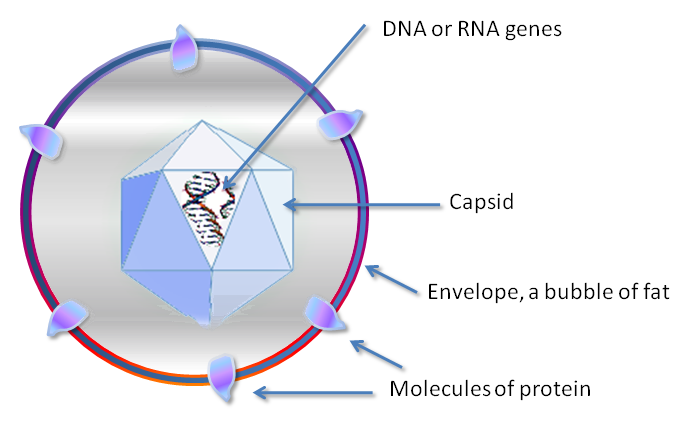
Viral particles are composed of:
- Nucleic acids (not only DNA)
- One or more protein layers that surround the nucleic acid, prevent degradation and support the initial and final replication cycle phases (within the cell the virus will then get rid of these superficial layers, to give rise to a free genome that can be exploited by the cell to give rise to the new particles)
Viruses are very different in size and structure, so classifying viruses with a taxonomic and phylogenetic objective is extremely complex. There are various classifications (e.g. based on morphology or pathogenicity).
Baltimore Classification
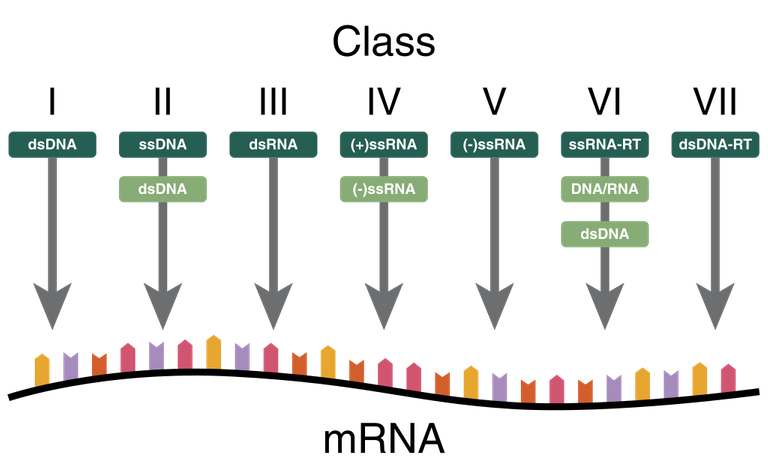
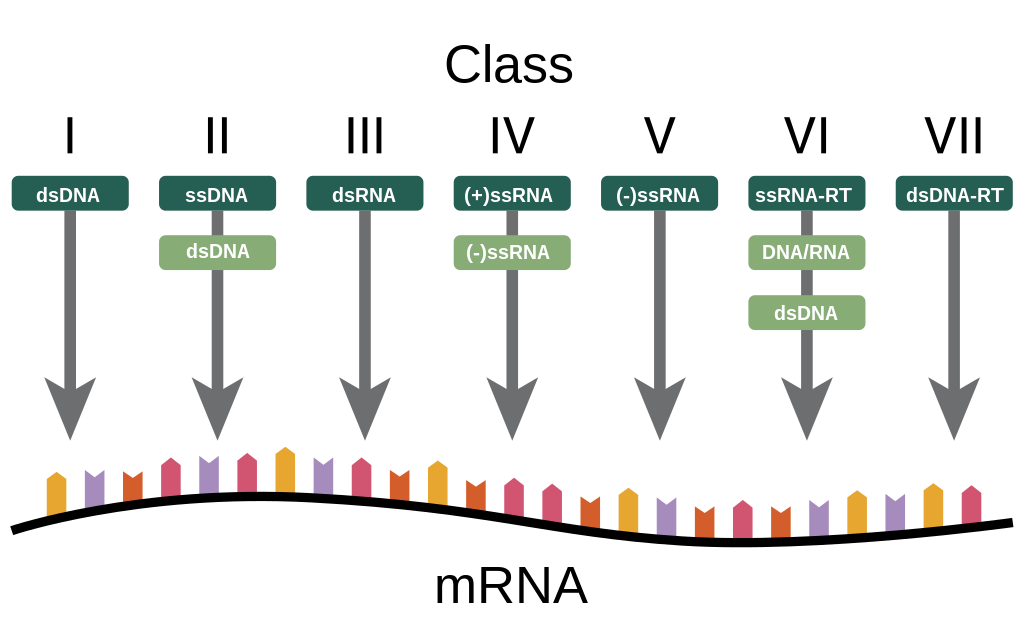
One of the most used classifications is the one based on the type of nucleic acid present in viruses, this classification is called Baltimore classification (it is NOT a taxonomic classification, in fact there are viruses belonging to different families).
This classification allows to identify some analogies of behavior between viruses of the same class, for example a virus that has as nucleic acid DNA needs to go to the nucleus of the cell, while a virus to RNA generally remains in the cytoplasm.
However, we remember that in biology we must never make a generalization because there are viruses, such as that of influenza, which despite being to RNA replicates in the nucleus.
This classification identifies 5 different classes of Baltimore viruses:
Double strand DNA or Class I of Baltimore
Single strand DNA or class II
Double strand RNA or III class
Single strand RNA with positive polarity or class IV
Single strand RNA with positive polarity or V class
The second class of Baltimore, which is that of single strand DNA, does NOT distinguish between positive and negative polarity because there are no viruses that have either one or the other helix, generally viruses that have only one helix randomly take it (or the positive or the negative) while RNA viruses are distinguished between those with positive polarity and those with negative polarity.
In addition to the five classes listed above, there are two other classes:
RNA viruses that go from an intermediate to DNA (they have the back-transcriptase enzyme that can obtain DNA from RNA)
DNA virus passing from an intermediate to RNA (they also have the back-transcriptase enzyme)
This class includes the medically relevant hepatitis B virus.
This classification therefore marks the behaviour of the virus in the cells and is also useful for pathogenesis.
An RNA virus, at least theoretically, can be completely eliminated while no DNA virus can be completely eliminated by the body. This is why patients with hepatitis C (RNA viruses) are treated while patients with hepatitis B (DNA viruses) can be considered cured at a clinical level but not at a virological level.
Transcription and translation
The genomes of viruses, just like those of cells, aim to synthesize proteins:
- Structural proteins
- Enzymes (which will be used to replicate the virus)
Viral transcripts are obtained from the viral genome, which are then taken to the cellular ribosomes where viral proteins useful for the progeny are obtained.
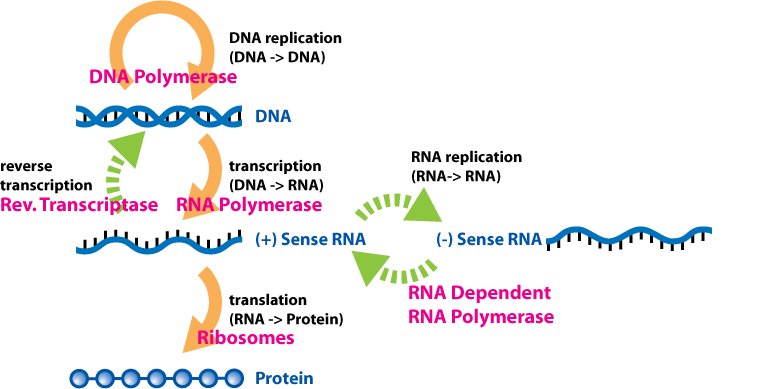
To obtain these transcripts the mechanism is the canonical one and it will be carried out in the presence of an RNA polymerase DNA dependent, however there are some exceptions.
Special cases:
- The RNA virus with positive polarity must make a copy of the RNA (which will be at negative polarity) in order to arrive at a mRNA and from this it will make a new copy obtaining the mRNA.
- For the virus to RNA to negative polarity a copy to direct complementarity will be had (an RNA is obtained from a mould of RNA thanks to an RNA polymerase dependent RNA). This is an anomalous procedure because usually the cell obtains RNA starting from DNA, in fact this enzyme is NOT possessed by the cell but it is a virus-specific enzyme (all viruses that possess genome to RNA have a gene that encodes for this essential enzyme).
In general, in the cell the virus carries all the material needed to get to the first transcripts. The only class of virus that does not need material to support its replication cycle is that of double strand DNA viruses, which are therefore considered directly infectious (the genome is sufficient to give infection).
Capsidic structure
Outside, the genome of the virus is covered with a protein shell called a capsid.
It is necessary that this capsid is made from many copies of a few proteins, this is because the nitrogenous bases are quite large as molecules, while the amino acids are quite small so knowing that to encode an amino acid I need 3 nitrogenous bases if I encode for many different proteins I would have many base pairs in the genome and consequently an excessive size.
These proteins are assembled to form a structure that has 2 properties:
Rigidity: to ensure the protection of the genome from the external environment
Reversability: because as soon as the virus enters the cell, the shell must release the nucleic acid by degradating
The passage from one structure to another is due to the ionic and Ph variations between the inside and the outside of the cell.
The capsid is present in 2 different symmetries:
- Helicidal: made from a single type of protein that multimerizes giving long protein chains that spiral around the nucleic acid. The proteins of the spiral can interact in different points with bonds that are not covalent (because at a certain point the capsides leave the nucleic acid) but strong enough to generate these solid structures. In this structure it is important that all the subunits are equal otherwise holes would be generated. Generally this structure is characteristic of RNA viruses (because RNA is a molecule more delicate than DNA and the capsidic protein also has the function, in the internal part, of stabilizing nucleic acid by doing an action similar to that of histones).
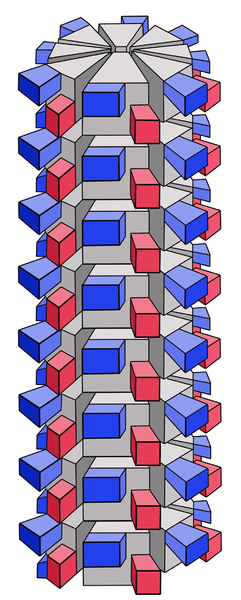
ICosahedral: each face is made from one or two proteins while, the vertex is made from a different protein. The faces are always multiple of 20. Given the large number of faces (up to 60), what appears from the outside is a sphere
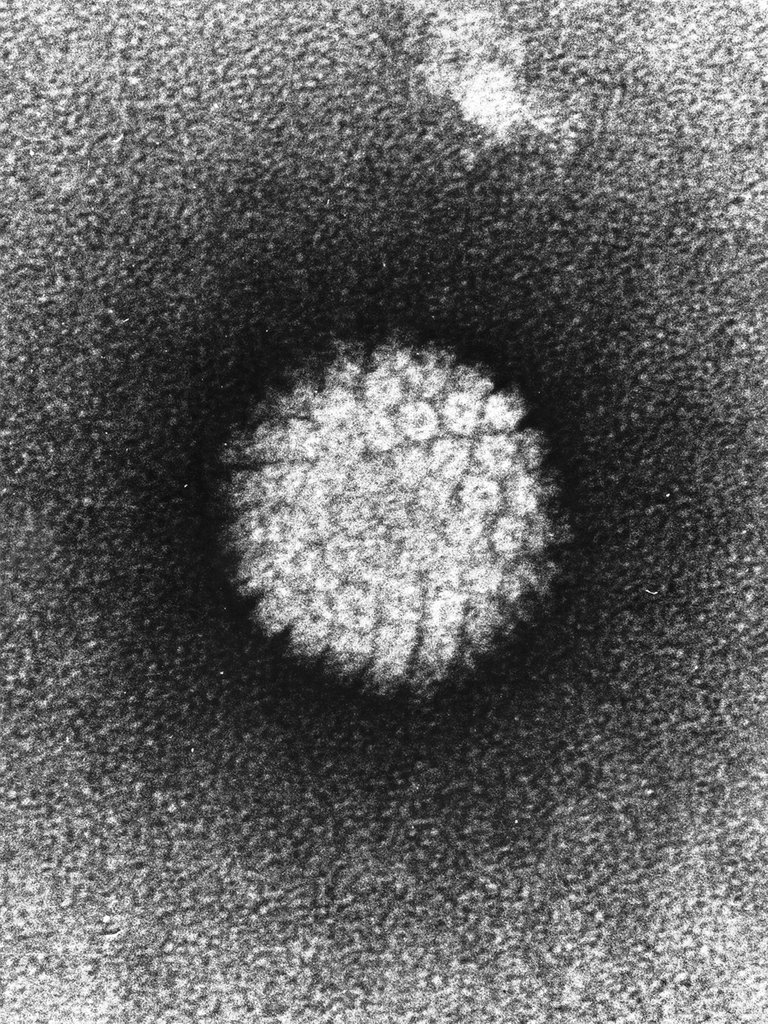
The characteristics of the viruses (type of nucleic acid, type of capsid, presence of pericapside) are inherent in the biology of that specific virus, do not vary. There is no modulation, as often happens in cells and bacteria.
Viruses are always the same, every single piece of the virus is a more than essential structure for the viral particle to be infectious.
Pericapse
Viruses are distinguished by:
Naked viruses: they only have genome and capsid
Virus with envelope: on the outside of the capsid they have a second layer called pericapside, or envelope, or envelope.
The pericapside, which surrounds the capsid, is NOT a properly viral structure because it is formed for the most part by something that originates from the virus-infected cell. The pericapside in particular originates from a cell membrane (nuclear membrane, Golgi membrane, cell membrane...) so it is a double phospholipid layer.
The presence or absence of the pericapside greatly influences the virus-cell interaction.
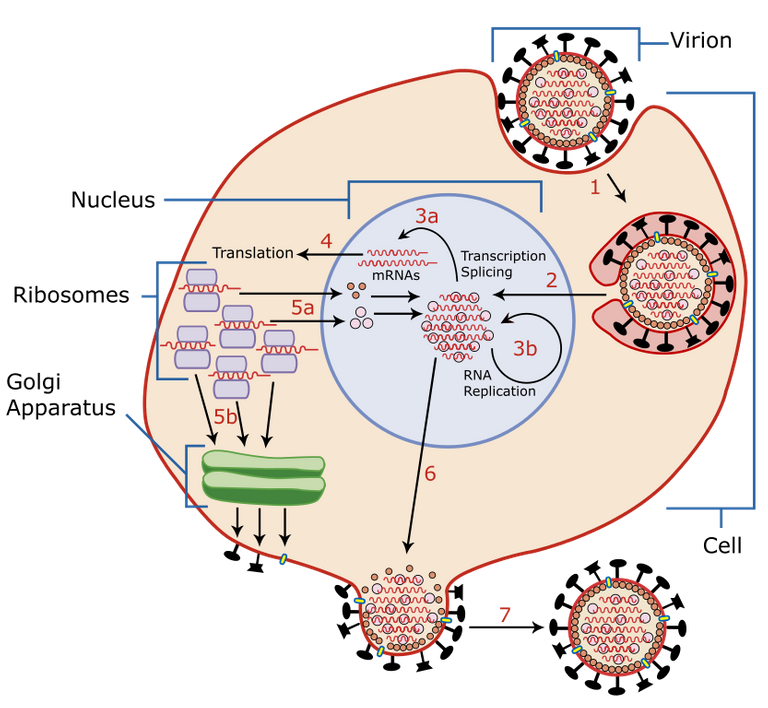
Process of virus replication
The process of virus replication within a cell is divided into 6 phases: 3 early phases and 3 late phases.
Early stages
1. Hooking the virus onto the cell to be infected
The purpose of the acellulated virus is to infect a cell. This is allowed by the fact that the virus has surface proteins that will be hooked by the cells through macromolecular interaction. The virus has a passive propulsion (wind, sneezing ...) and when it comes into contact with a cell that has viral anti-receptors on its surface (molecules that are able to bind with high affinity the surface proteins of the virus) it attaches to it.
As far as viruses with envelopes are concerned, when they come into contact with a cell, the pericapside (formed by a cell membrane) merges with the cell membrane of the cell hooked by the virus. If this happens randomly, the cell may not be suitable to support the replication cycle of that specific virus (for example, if the virus enters a cell in apoptosis). Then enveloped viruses modify the membranes that will form the pericapside by adding virus-specific proteins that will act as viral receptors. Between the viral receptors and the viral anti-receptors the link can be extremely selective (example: HIV binds CD4 expressed only on some human cells) or less selective (example: influenza virus binds some types of sialic acids, present on the cell membranes of all organisms, in fact we can take viruses of other species). Therefore, a necessary but NOT sufficient condition for the cell to be infected by a virus is that the virus possesses the viral receptor and the cell possesses the viral anti-receptor. Another condition is that the virus passes very close to the cell in order to determine the attachment that will then cause a series of downstream reactions (such as receptor mediated endocytosis).
2. Penetration into the host cell
There are two ways in which this can happen
Mediated receptor endocytosis (most common for naked viruses)
Cell membrane fusion (most common in enveloped viruses).
When two cell membranes are brought close together, the two protein receptors engage and this leads to conformational changes in the proteins that bend to bring the virus closer to the cell membrane. When this happens, the two membranes can fuse and the capsid is released inside the cytoplasm (not covered by a bladder as is the case with receptor mediated endocytosis).
3. Scapsidation
Viruses that enter the cell need to get rid of the capsid. For example, the influenza virus (which, despite being enveloped, enters through endocytosis mediated receptor) once it enters the cell is caged in the endocytotic vesicle. In the vesicle we have strong pH alterations, they are acidified (for example through hydrogen pumps on the vesicle) and this generates a complete destabilization of the capsid. Therefore, at the same time as the envelope merges with the vesicle membrane, the capsid is destabilised.
Acidification leads to a change in the ionic forces that hold the capsidic proteins together. Another phenomenon that can lead to scapsidation is the change in ion concentration, for example for Rotavirus we will have an alteration in the concentration of calcium ions and this will destabilize the surface layers of the capisde. In general, the objective of scapsidation is to release the capsid in a non-aggressive manner, i.e. without degrading enzymes, and release the nucleic acid.
In some cases this process occurs only at the nuclear level, so for example the Herpes will bring the capsid to the level of the nuclear pores, where there will be a phenomenon still not completely known through which the capsid is destructured and the nucleic acid is released into the nucleus.
Late stages
4. Genome replication and protein synthesis
Replication of the virus depends on the type of nucleic acid.
Transcription is allowed both by specific virus enzymes (enzymes that are not present in the cell and are therefore synthesized by the virus because they are necessary for its replication cycle) and by cell enzymes. The Double strand DNA virus generally does not need the specific enzymes virus, it uses only the cellular machinery.
E.g. Herpetic virus (Baltimore class I): as the envelope enters by fusion inside the cell membrane, it will bring the capsid to the level of the nuclear membrane, it will introduce the nucleic acid into the nucleus and it will be initially managed by a DNApolymerase-DNA-dependent and by a RNApolymerase-RNA-dependent that will trigger the viral replication.
Replication must always give rise to:
Transcribed for proteins
Genome copy (they will be placed inside the newly synthesized heads)
The virus in the subsequent stages will give rise to a viral DNA-polymerase much more efficient than cellular DNA-polymerase (which is only used initially) because it is not linked to all cellular regulatory processes. In fact, a cell takes days to copy the DNA while the herpetic virus takes about 8 hours.
The replication of viruses to DNA takes place in the nucleus, while that of viruses to RNA (which often depend on viral enzymes) are replicated at the cytoplasmic level.
Replication of double filament viruses is NOT semi-conservative (with an original propeller and a newly synthesised one) but both filaments will be newly synthesised.
Example: from an RNA with negative polarity with RNApolymerase-dependent RNA, RNA with positive polarity will be obtained. A single copy of this enzyme must go inside the cell with a single copy of the genome because this will allow to make a single copy of transcript from which will synthesize many copies of RNApolymerase-RNA dependent. These enzymes will then synthesize many copies of positive polarity ANNs and starting from these will have origin many copies of negative polarity ANNs, each of which will be equipped with a copy of the initially synthesized RNApolymerase-RNA-dependent RNAs. Therefore the positive polarity ANN will have a double role, on one hand it will do the transcripts and on the other it will act as a mould for the new genomes.
The viruses have evolved a series of mechanisms that push the cell to synthesize a great quantity of viral material, leaving out the processes useful to the cell. One of these is the Shut-Off gene, the virus in addition to the transcripts, synthesizes a protease that goes to prevent the reading of the transcripts of the cell because it goes to make degradation of the complex of initiation of the reading of the canonical transcripts (switches off the synthesis of the cell) making available all the replicative apparatus of the cell to the virus. It is therefore a form of active and absolute parasitism. The cells will almost always suffer from the presence of the virus, in some cases the phenomenon is a little more symbiotic.
5. Assembly
The virus is covered by the capsid and a membrane that will form the pericapside (e.g. the nuclear membrane).
6. Release of viruses
Once the viral particle is matured inside the cell it must succeed in exiting, this can be done with 3 modes:
Cellysis (typical of naked viruses): this is an output that does not respect the integrity of the host cell.
Remembrance or budding (typical of viruses with envelopes): it is a release that respects the integrity of the host cell; in certain areas of the cell membrane the proteins of the pericapside are mounted, they attract the capsid and the complex, pushing from the inside, leads to the detachment of a vesicle that will be the viral envelope. This is a similar exocytotic process
Exocytosis: If the pericapside is formed by another membrane (such as the Golgi membrane), the complex exocytosis occurs. This phenomenon can also occur with naked viruses. The integrity of the cell is also respected in this case.
For exocytosis, both enveloped and unencapsulated viruses can be released, for lysis almost always those without envelopes, but for example also herpes viruses despite presenting it. The choice of output mode is determined by how the virus used the cell. If the virus has exploited it to the maximum, turning off the protein synthesis, the output will be through lysis.
Genetic heritage of viruses
The virus needs to make the most of its genetic heritage. The genome of the virus is very small:
The average size of the genome is 10,000 to 30,000 base pairs, ranging from 3.5 to 200 Kilobases.
The average size of a gene is 1000 bases
So on average on a viral genome is contained the information for 5 proteins
This is because on a sequence of nitrogenous bases there is the possibility of having more than one different reading frame, it is a mechanism that allows me to obtain more proteins (different from each other) from the same fragment.
Another way to get different transcripts and optimize the reduced amount of nucleic acid present is the alternative splicing.
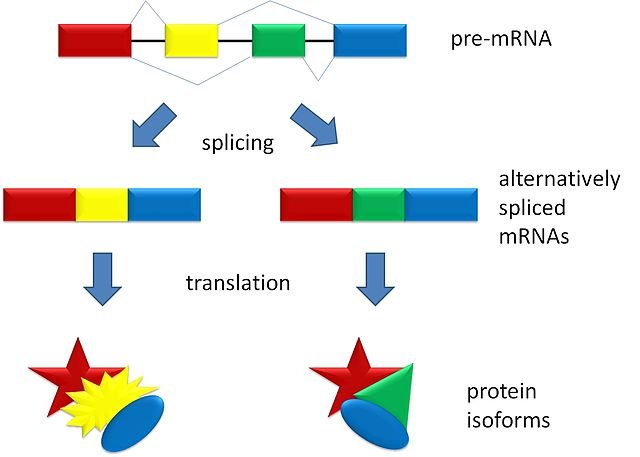
This phenomenon is evident on the Hepatitis B virus, which has the smallest known genome (about 3 kilobases) on which there is a massive reading overlap (the same fragment can be read in several ways). This characteristic allows the different biological qualities typical of the virus, including the poor ability to mutate. For Hepatitis B there is a vaccine, for HIV no because it has great capacity for mutation.
The Hepatitis B virus uses reverse transcriptase which does NOT have proof-reading capacity, given the large number of errors, Hepatitis B is saved because it has this ability to make three different proteins on the same gene fragment.
If a mutation occurs on Hepatitis B, surely one of the three proteins will no longer be functional, so all the mutations inserted are eliminated and this brings stability to the genetic level. The strong functional constraint brought to the virus by the fact that it uses the same gene fragment to make different proteins limits their evolutionary capacity (reading the same gene fragment 3 times means keeping the original sequence).
The HIV virus, which uses transcriptase like the Hepatitis B virus, mainly does alternative splicing and does not make multiple readings of the same frame so it can change as much as it wants.
I hope you enjoyed this introduction to this world and I look forward to the next article :)
Virus
Ciao a tutti amici, oggi in questa nuova rubrica andremo a fare un introduzione sulla Virologia, cominceremo a vedere cosa sono i Virus, come sono classificati, come agiscono e come funzionano a livello biologico/molecolare, come replicano e molto altro ancora, buona lettura.
Introduzione
I virus possono essere definiti come organismi in quanto contengono genoma.
Un organismo tuttavia, viene solitamente definito come qualcosa composto da una singola cellula (unicellulare) o da più cellule (pluricellulare) mentre i virus sono organismi acellulari.
Oltre al genoma il virus contiene strutture che gli permettono di proteggersi dall’ambiente esterno e di andare a replicare all’interno della cellula che lo ospita, quindi sono considerati parassiti intracellulari obbligati.
La cellula che verrà infettata farà tutte le attività necessarie alla replicazione dell’organismo al posto del virus.
Il virus ha una replicazione anomala, infatti una singola particella virale (detta virione) infettando una singola cellula nell’ambito di un singolo ciclo replicativo può dare origine a migliaia di particelle virali figlie.
Quindi in questa struttura apparentemente semplice è insita una grande efficienza.
Le particelle virali sono composte da:
• Acidi nucleici (non solo DNA)
• Uno o più strati proteici che circondano l’acido nucleico, ne impediscono la degradazione e supportano le fasi di ciclo replicativo iniziali e finali (all’interno della cellula il virus si libererà poi di questi strati superficiali, per dare origine a un genoma libero che potrà essere sfruttato dalla cellula per dare origine alle nuove particelle)
I virus sono molto diversi dimensionalmente e strutturalmente tra loro quindi classificare i virus con un obiettivo tassonomico e filogenetico è estremamente complesso. Esistono varie classificazioni (per esempio in base alla morfologia o alla patogenicità).
Classificazione di Baltimore
Una delle classificazioni più utilizzate è quella in base al tipo di acido nucleico presente nei virus, questa classificazione è chiamata classificazione di Baltimore (NON è una classificazione tassonomica, infatti sono presenti virus che appartengono a diverse famiglie).
Questa classificazione permette di identificare alcune analogie di comportamento tra i virus della stessa classe, per esempio un virus che ha come acido nucleico il DNA ha la necessità di andare nel nucleo della cellula, mentre un virus a RNA generalmente rimane nel citoplasma.
Tuttavia ricordiamo che in biologia non bisogna mai fare una generalizzazione poiché ci sono virus, come quello dell’influenza, che pur essendo ad RNA replica nel nucleo.
Con questa classificazione si identificano 5 classi di Baltimore diverse di virus:
• Double strand DNA o I classe di Baltimore
• Single strand DNA o II classe
• Double strand RNA o III classe
• Single strand RNA a polarità positiva o IV classe
• Single strand RNA a polarità positiva o V classe
La seconda classe di Baltimore che è quella dei single strand DNA, NON distingue tra polarità positiva e polarità negativa perché non ci sono virus che hanno o una o l’altra elica, generalmente i virus che hanno una sola elica la prendono casualmente (o la positiva o la negativa) mentre i virus a RNA si distinguono tra quelli a polarità positiva e quelli a polarità negativa.
Oltre alle cinque classi precedentemente elencate sono presenti altre 2 classi:
• Virus a RNA che passano da un intermedio a DNA (possiedono l’enzima retrotrascrittasi che riesce ad ottenere DNA partendo da RNA)
• Virus a DNA che passa da un intermedio a RNA (anche essi possiedono l’enzima retrotrascrittasi)
Questa classe comprende il virus dell’Epatite B rilevante dal punto di vista medico.
Questa classificazione quindi segna il comportamento del virus nelle cellule ed è utile anche per la patogenesi.
Un virus a RNA, almeno a livello teorico, può essere eliminato completamente mentre nessun virus a DNA può essere eliminato completamente dall’organismo. Questo è il motivo per cui i pazienti affetti da epatite C (virus a RNA) si curano mentre i pazienti affetti da epatite B (virus a DNA) possono considerarsi guariti a livello clinico ma non a livello virologico.
Trascrizione e traduzione
I genomi dei virus, proprio come quelli delle cellule hanno l’obiettivo di sintetizzare proteine:
• Proteine strutturali
• Enzimi (che serviranno a far replicare il virus)
Dal genoma virale si ottengono trascritti virali, che poi saranno portati sui ribosomi cellulari dove si otterranno delle proteine virali utili per la progenie.
Per ottenere questi trascritti il meccanismo è quello canonico e si effettuerà in presenza di una RNA polimerasi DNA dipendente, tuttavia vi sono alcune eccezioni.
Casi particolari:
- Il virus a RNA a polarità positiva per poter arrivare ad un mRNA deve fare una copia dell’RNA (che sarà a polarità negativa) e da questa farà una nuova copia ottenendo l’mRNA
- Per il virus a RNA a polarità negativa si avrà una copia a complementarietà diretta (si ottiene un RNA da uno stampo di RNA grazie a un RNA polimerasi-RNA dipendente). Questo è un procedimento anomalo perché di solito la cellula ottiene RNA partendo da DNA, infatti questo enzima NON è posseduto dalla cellula ma è un enzima virus-specifico (tutti i virus che possiedono genoma a RNA hanno un gene che codifica per questo enzima essenziale).
In generale nella cellula il virus porta tutto il materiale necessario per arrivare ai primi trascritti. L’unica classe di virus che non ha bisogno di materiale per supportare il proprio ciclo replicativo è quella dei virus double strand DNA, che sono per questo considerati direttamente infettanti (il genoma è sufficiente a dare infezione).
Struttura capsidica
All’esterno il genoma del virus è ricoperto da un guscio proteico chiamato capside.
È necessario che questo capside sia fatto da tante copie di poche proteine, questo perché le basi azotate sono piuttosto grosse come molecole, mentre gli amminoacidi sono piuttosto piccoli quindi sapendo che per codificare un amminoacido ho bisogno di 3 basi azotate se codificassi per molte proteine diverse avrei molte paia di basi nel genoma e di conseguenza un eccessivo ingombro dimensionale.
Queste proteine si assemblano per formare una struttura che ha 2 proprietà:
• Rigidità: per garantire la protezione del genoma dall’ambiente esterno
• Reversibilità: perché appena il virus entra nella cellula il guscio deve liberare l’acido nucleico degradandosi
Il passaggio da una struttura e l’altra è dovuto alle variazioni ioniche e di Ph tra l’interno e l’esterno della cellula.
Il capside è presente in 2 diverse simmetrie:
• Elicoidale: fatta da un solo tipo di proteina che multimerizza dando lunghe catene proteiche che si organizzano a spirale attorno all’acido nucleico. Le proteine della spirale possono interagire in diversi punti con legami non covalenti (perché i capsidi ad un certo punto abbandonano l’acido nucleico) ma abbastanza forti da generare queste strutture solide. In questa struttura è importante che tutte le subunità siano uguali altrimenti si genererebbero dei buchi. Generalmente questa struttura è caratteristica dei virus ad RNA (perché l’RNA è una molecola più delicata del DNA e la proteina capsidica ha anche la funzione, nella parte interna, di stabilizzazione dell’acido nucleico facendo un’azione simile a quella degli istoni)
• Icosaedrica: ogni faccia è fatta da una o due proteine mentre, il vertice è fatto da una proteina differente. Le facce sono sempre multipli di 20. Visto l’elevato numero di facce (fino a 60), ciò che appare dall’esterno è una sfera
Le caratteristiche dei virus (tipologia di acido nucleico, tipologia di capside, presenza del pericapside) sono insite nella biologia di quello specifico virus, non variano. Non è presente una modulazione, come avviene spesso nelle cellule e nei batteri.
I virus sono sempre uguali, ogni singolo pezzo del virus è una struttura più che essenziale perché la particella virale possa essere infettante.
Pericapside
I virus si distinguono in:
• Virus nudi: possiedono solamente genoma e capside
• Virus con envelope: all’esterno del capside possiedono un secondo strato chiamato pericapside, o involucro, o envelope appunto
Il pericapside, che va a circondare il capside, NON è una struttura propriamente virale perchè è formato per gran parte da qualcosa che è originato dalla cellula infettata dal virus. Il pericapside in particolare origina da una membrana della cellula (membrana nucleare, membrana del Golgi, membrana cellulare…) quindi è un doppio strato fosfolipidico.
La presenza o l’assenza del pericapside influenza notevolmente l’interazione virus-cellula.
Processo di replicazione dei virus
Il processo di replicazione dei virus all’interno di una cellula si divide in 6 fasi: 3 fasi early e 3 fasi late.
Fasi precoci
1. Aggancio del virus sulla cellula da infettare
ll virus essendo acellulato ha l’obiettivo di infettare una cellula. Questo è permesso dal fatto che il virus ha delle proteine di superficie che verranno agganciate dalle cellule attraverso un’interazione macromolecolare. Il virus ha una propulsione passiva (vento, starnuto …) e quando entra in contatto con una cellula che possiede sulla propria superficie degli antirecettori virali (molecole che sono in grado di legare con alta affinità le proteine superficiali del virus) si aggancia ad essa.
Per quanto riguarda i virus con envelope, quando essi entrano a contatto con una cellula, il pericapside (formato da una membrana della cellula) si fonde con la membrana cellulare della cellula agganciata dal virus. Se questo avvienisse in maniera totalmente casuale, la cellula potrebbe non essere adatta per sostenere il ciclo replicativo di quello specifico virus (per esempio nel caso in cui il virus entri in una cellula in apoptosi). Quindi i virus con envelope modificano le membrane che formeranno il pericapside aggiungendo proteine virus-specifiche che fungeranno da recettori virali. Tra i recettori virali e gli antirecettori virali il legame può essere estremamente selettivo (esempio: HIV che lega il CD4 espresso solo su alcune cellule umane) oppure meno selettivo (esempio: virus dell’influenza che lega alcuni tipi di acidi sialici, presenti sulle membrane delle cellule di tutti gli organismi, infatti noi possiamo prendere virus anche di altre specie). Quindi condizione necessaria, ma NON sufficiente, perchè la cellula possa essere infettata da un virus è che il virus possieda il recettore virale e la cellula possieda l’antirecettore virale. Un’altra condizione è che il virus passi molto vicino alla cellula in modo da determinare l’aggancio che successivamente provocherà una serie di reazioni a valle (come l’endocitosi recettore mediata)
2. Penetrazione nella cellula ospite
Esistono due modalità con le quali può avvenire
• Endocitosi recettore mediata (più comune per i virus nudi)
• Fusione a livello della membrana cellulare (più comune nei virus con envelope).
Quando si portano due membrane cellulari vicino tra loro, i due recettori proteici si agganciano e questo porta a dei cambi conformazionali delle proteine che si piegano per fare avvicinare il virus alla membrana cellulare. Quando questo avviene le due membrane possono fondersi e viene rilasciato all’interno del citoplasma il capside (non ricoperto da una vescica come avviene invece per l’endocitosi recettore mediata).
3. Scapsidazione
I virus una volta entrati nella cellula necessitano di liberarsi dal capside. Per esempio il virus dell’influenza (che pur essendo con envelope entra attraverso endocitosi recettore mediata) una volta entrato nella cellula è ingabbiato nella vescicola endocitotica. Nella vescicola abbiamo forti alterazioni di pH, esse vengono acidificate (per esempio attraverso pompe idrogeno sulla vescicola) e questo genera una destabilizzazione completa del capside. Quindi contemporaneamente alla fusione dell’envelope con la membrana della vescicola avviene la destabilizzazione del capside.
L’acidificazione porta ad un cambiamento delle forze ioniche che tengono insieme le proteine capsidiche. Un altro fenomeno che può determinare la scapsidazione è la variazione della concentrazione ionica, per esempio per i Rotavirus avremo un’alterazione della concentrazione degli ioni calcio e questo destabilizzerà gli strati superficiali del capisde. In generale l’obiettivo della scapsidazione è quello di sganciare in maniera non aggressiva, quindi senza enzimi degradativi, il capside e rilasciare l’acido nucleico.
In alcuni casi questo processo avviene soltanto a livello nucleare, quindi per esempio l’Herpes porterà il capside a livello dei pori nucleari, dove avverrà un fenomeno ancora non completamente noto attraverso il quale il capside si destruttura e l’acido nucleico viene liberato nel nucleo.
Fasi tardive
4. Replicazione del genoma e sintesi proteica
La replicazione del virus dipende dal tipo di acido nucleico.
La trascrizione è permessa sia da enzimi virus specifici (enzimi che non sono presenti nella cellula e sono quindi sintetizzati dal virus perché necessari al suo ciclo replicativo) sia dagli enzimi della cellula. Il virus a Double strand DNA generalmente non ha bisogno degli enzimi virus specifici, utilizza esclusivamente la machinery cellulare.
Es. Virus erpetico (classe I di Baltimore): avendo l’envelope entra per fusione all’interno della membrana cellulare, porterà il capside a livello della membrana nucleare, immetterà l’acido nucleico nel nucleo ed esso verrà gestito inizialmente da una DNApolimerasi-DNA dipendente e da una RNApolimerasi-RNA dipendente che innescherà la replicazione virale.
La replicazione deve dare sempre origine a:
• Trascritti per le proteine
• Copia dei genomi (saranno inseriti all’interno dei capsidi neosintetizzati)
Il virus nelle fasi successive darà origine a una DNApolimerasi virale molto più efficiente di quella cellulare (che viene utilizzata solo inizialmente) perché non è legata a tutti i processi di regolazione cellulari. Infatti una cellula impiega giorni per copiare il DNA mentre il virus erpetico impiega circa 8 ore.
La replicazione di virus a DNA avviene nel nucleo, mentre quella dei virus a RNA (che dipendono spesso da enzimi virali) vanno a replicarsi a livello citoplasmatico.
Amplificazione
La replicazione dei virus a doppio filamento NON è semiconservativa (con un’elica originale e una di nuova sintesi) ma entrambi i filamenti saranno di nuova sintesi.
Esempio: da un RNA a polarità negativa con RNApolimerasi-RNA dipendente si otterrà RNA a polarità positiva. Una singola copia di questo enzima deve andare all’interno della cellula con una singola copia del genoma perché questo permetterà di fare una singola copia di trascritto dal quale si sintetizzeranno tante copie di RNApolimerasi-RNA dipendente. Questi enzimi poi sintetizzeranno tante copie di RNA a polarità positiva e partendo da queste avranno origine tante copie di RNA a polarità negativa, ognuna delle quali verrà dotata di una copia delle RNApolimerasi-RNAdipendenti sintetizzate inizialmente. Quindi l’RNA a polarità positiva avrà un doppio ruolo, da una parte farà i trascritti e dall’altra farà da stampo per i nuovi genomi.
I virus hanno evoluto una serie di meccanismi che spingono la cellula a sintetizzare una grande quantità di materiale virale, tralasciando i processi utili alla cellula. Uno di questi è lo Shut-Off genico, Il virus oltre ai trascritti, sintetizza una proteasi che va a impedire la lettura dei trascritti della cellula perché va a fare degradazione del complesso di iniziazione della lettura dei trascritti canonici (spegne la sintesi della cellula) rendendo disponibile tutto l’apparato replicativo della cellula al virus. È quindi una forma di parassitismo attivo e assoluto. Le cellule entreranno quasi sempre in sofferenza per la presenza del virus, in alcuni casi il fenomeno è un po’ più simbiotico.
5. Assemblaggio
Il virus viene ricoperto dal capside e da una membrana che formerà il pericapside (per esempio la membrana nucleare).
6. Rilascio dei virus
Una volta che la particella virale è maturata dentro la cellula deve riuscire a uscire, questo può avvenire con 3 modalità:
• Lisi della cellula (tipica dei virus nudi): è un’uscita non rispettosa dell’integrità della cellula ospite
• Gemmazione o budding (tipica dei virus con envelope): è un rilascio rispettoso dell’integrità della cellula ospite; in determinate zone della membrana cellulare sono montate le proteine del pericapside, esse attraggono il capside e il complesso, spingendo dall’interno, porta al distacco di una vescicola che sarà l’envelope virale. Si tratta di un processo simil esocitotico
• Esocitosi: se il pericapside è formato da un’altra membrana (come la membrana del Golgi) avviene l’esocitosi del complesso. Questo fenomeno può avvenire anche per i virus nudi. Anche in questo caso viene rispettata l’integrità della cellula.
Per esocitosi possono uscire sia i virus con envelope sia senza envelope, per lisi quasi sempre quelli senza envelope, ma per esempio anche gli herpes virus nonostante lo presentino. La scelta della modalità di uscita è determinata da come il virus ha utilizzato la cellula. Se il virus l’ha sfruttata al massimo, spegnendone la sintesi proteica, l’uscita avverrà attraverso la lisi.
Patrimonio genetico dei virus
Il virus hanno la necessità di sfruttare al meglio il proprio patrimonio genetico. Il genoma dei virus è molto piccolo:
• La dimensione media del genoma è di 10.000- 30.000 paia di basi, si parte da 3.5 a 200 Kilobasi
• La dimensione media di un gene è di 1000 basi
Quindi in media su un genoma virale è contenuta l’informazione per 5 proteine
Questo perché su una sequenza di basi azotate c’è la possibilità di avere più frame di lettura differenti, si tratta di un meccanismo che mi permette di ottenere più proteine (diverse tra loro) a partire da uno stesso frammento.
Un’altra modalità per ottenere trascritti diversi e ottimizzare al meglio la quantità ridotta di acido nucleico presente è lo Splicing alternativo.
Questo fenomeno è evidente sul virus dell’Epatite B, che ha il genoma più piccolo conosciuto (circa 3 kilobasi) sul quale è presente una sovrapposizione di lettura imponente (lo stesso frammento può essere letto in svariati modi). Questa caratteristica permette le diverse qualità biologiche tipiche del virus, tra cui la scarsa capacità di mutare. Per l’Epatite B esiste un vaccino, per HIV no poiché ha grandi capacità di mutazione.
Il virus dell’Epatite B utilizza la retrotrascrittasi che NON ha la capacità proof-reading, visto il notevole numero di errori, l’Epatite B si salva perché ha questa capacità di fare tre proteine diverse sullo stesso frammento genico.
Se avviene una mutazione sull’Epatite B, sicuramente una delle tre proteine non sarà più funzionale, quindi tutte le mutazioni inserite vengono eliminate e questo arreca stabilità a livello genetico. La forte costrizione funzionale portata al virus dal fatto di utilizzare lo stesso frammento genico per fare proteine diverse limita la loro capacità evolutiva (leggere per 3 volte lo stesso frammento di un gene significa mantenere la sequenza originale).
Il virus dell’HIV, che utilizza retrotrascrittasi come il virus dell’Epatite B, fa prevalentemente splicing alternativo e non fa letture multiple dello stesso frame quindi può mutare quanto vuole.
spero che questa introduzione in questo mondo vi sia piaciuta e vi aspetto al prossimo articolo :)
fonti/sources
immagini/pictures
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_EM.jpg){kind=link}
{kind=link}
{kind=link}

This post was selected, voted and shared by the discovery-it curation team in collaboration with the C-Squared Curation Collective. You can use the #Discovery-it tag to make your posts easy to find in the eyes of the curator. We also encourage you to vote @c-squared as a witness to support this project.
Congratulations @riccc96! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Viruses are interesting and it was a shame that virology was a high level university course where I went to school. Meaning, it was hard to fit into your schedule once you reach your third or fourth year unless you are planning on doing graduate degrees in them.
I understand very well, it is a course really very nice but complicated, in our university is resumed twice, in medical microbiology and again in clinical microbiology, it is a pity that it is taught so little in other courses
Way above my head my friend. I will need a year of Sundays to read and dissect this post and at my age I will have forgotten all in the second year Lol.
But I can see that you have put a lot of effort into the post and you have my congratulations!
Blessings!