Fehlertoleranz in Computersystemen: Fehlererkennung und Fehlerkorrektur, Paritätsbit
Um einen Fehler tolerieren zu können, muss zunächst erkannt werden dass ein Fehler aufgetreten ist. Erst dann kann das System die notwendigen Schritte unternehmen, um korrigierende Maßnahmen in die Wege zu leiten. Man unterscheidet daher zwischen Fehlererkennung und Fehlerkorrektur.
Bitfehler
Bitfehler können während des Ablaufs eines Programms in der CPU auftreten, oder bei der Übertragung von Daten zu anderen Systemkomponenten durch das Übertragungssystem eingeführt werden. Eine andere Fehlerquelle ist die Langzeitarchivierung von Daten auf Festplatten. Während den Bitfehlern in einem Computer meist ein Defekt in der Hardware zugrunde liegt, sind es Umwelteinflüsse wie Strahlung, Temperatur und magnetische Induktion die das Fehlverhalten eines Datenübertragungssystems und eines Langzeitspeichers beeinflussen.
Es gibt zwei Arten von Bitfehlern:
- einfache Bitfehler (isolierte Bits)
- Fehlerfolgen (Burst-Errors), also Gruppen aufeinanderfolgender Bitfehler
Obwohl die Wahrscheinlichkeit eines Bitfehlers mit moderner Technologie abnimmt, sind Übertragungsfehler und Archivierungsfehler (flipped bits) unvermeidbar.
Um Fehler dieser Art tolerieren zu können müssen Methoden entwickelt werden, die es ermöglichen mit solchen Fehlern umzugehen. Es ist eventuell möglich auftretende Fehler zu korrigieren. Wenn dies nicht möglich ist muss der fehlerbehaftete Datenblock verworfen werden. Mann kann allerdings in einigen Systemen die Fehlerüberwachung auf die Erkennung von Fehlern beschränken und auf die explizite Korrektur eines Fehlers verzichten. Das wird insbesondere im Gebiet der Datenübertragung (TCP/UDP) deutlich, bei der fehlerbehaftete Datenpakete generell eliminiert werden.
Um aufgetretene Fehler erkennen und möglicherweise korrigieren zu können, müssen zusätzliche Informationen verfügbar gemacht werden, die darüber Aufschluss geben können ob und wo ein Fehler aufgetreten ist, also welche Bitpositionen einen Fehler aufweisen.
Diese Zusatzinformation muss natürlich dem ursprünglichen Datenblock zugeordnet werden. Somit erhöht sich gleichzeitig die Anzahl der Bits, die notwendig sind, um den Datenblock zu speichern oder zu übertragen. Die zusätzlichen Bits, die zur Fehlererkennung oder Korrektur von Fehlern dienen, werden als Redundanzbits bezeichnet, da sie nicht zur Speicherung oder Übertragung der eigentlichen Information dienen.
Paritätsbits und Paritätscodierung
Die einfachste Methode redundante Bitstellen in einem Code so einzufügen, dass Fehler erkannt oder sogar korrigiert werden können, ist die Berechnung der Parität. Die Parität ist die Information darüber, ob ein bestimmtes Codewort eine gerade oder ungerade Anzahl an Bitstellen besitzt, die eine logische 1 enthalten.
Man unterscheidet die gerade und ungerade Parität, wobei ein Paritätsbit dem Datenwort hinzugefügt wird, welches den Wert 1 oder 0 enthält, je nachdem wie viele Datenbits den Wert 1 aufweisen und welche Parität man anwendet.
Bei einem geraden Paritätsprinzip wird dem Paritätsbit immer dann eine 1 zugewiesen, wenn die Anzahl der Datenbits mit dem Wert 1 ungerade ist. Somit wird gewährleistet, dass die Anzahl der 1-Bits in einem fehlerfreien Codewort immer gerade ist. Bei dem ungeraden Paritätsprinzip wird das Paritätsbit so gesetzt, dass die Anzahl der 1-Bits in einem fehlerfreien Codewort immer ungerade ist.
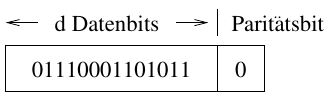
Abbildung 1: Datenbits mit geraden Paritätsprinzip
Das Paritätsbit lässt sich für das gerade Paritätsprinzip leicht durch eine Exklusive-Oder (XOR) Verknüpfung aller Datenbits berechnen. Der Einsatz eines Paritätsbits, ermöglicht allerdings nur die Erkennung von Fehlern. Da ein redundantes Bit nicht genug Information enthält um die genaue Bitposition eines Fehlers zu bestimmen, ist diese Methode auf Fehlererkennung limitiert.
Um die Fehlerkorrektur zu ermöglichen, muss zusätzliche Information in der Form von redundanten Bits bereitgestellt werden.
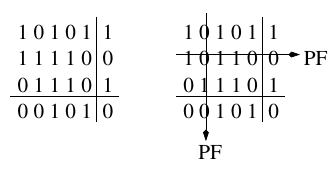
Abbildung 2: Fehlerkorrektur durch 2-dimensionale Parität, PF = Paritätsfehler
Ein aufgetretener Bitfehler ändert somit die Parität des jeweiligen Datenwortes (Querparität) und die Parität der jeweiligen Spalte des Datenblocks (Längsparität). Nachdem die Paritäten jedes der Datenworte und jeder der Spalten des Datenblocks berechnet wurden, kann die genaue Stelle eines Bitfehlers im Datenblock identifiziert werden.
Quelle
https://www.researchgate.net/publication/326597429_Two_Dimensional_Parity_Check_with_Variable_Length_Error_Detection_Code_for_the_Non-Volatile_Memory_of_Smart_Data
Koren, I. and Mani Krishna , C. (2007). Fault-Tolerant Systems. CA: Elsevier
Du hast ein Upvote von mir bekommen, diese soll die Deutsche Community unterstützen. Wenn du mich unterstützten möchtest, dann sende mir eine Delegation. Egal wie klein die Unterstützung ist, Du hilfst damit der Community. DANKE!
Congratulations @ozelot47! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board And compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider supporting our funding proposal, approving our witness (@stem.witness) or delegating to the @stemsocial account (for some ROI).
Please consider using the STEMsocial app app and including @stemsocial as a beneficiary to get a stronger support.