Fehlertoleranz in Computersystemen: Datenspeicherung auf RAID
RAID ist die Abkürzung für Redundant Array of Independent Disks, also ein redundantes Array unabhängiger Plattenspeicher.
RAID-0
Die einfachste Version eines RAID ist RAID-0. In dieser Konfiguration simuliert das RAID einen alleinstehenden Plattenspeicher, dessen Speicherkapazität in Streifen (englisch: stripes) mit je k Sektoren unterteilt ist, wobei die Sektoren auf den Streifen liegen.
Die Verteilung von Daten über eine Anzahl verfügbarer Disks wird generell als Striping bezeichnet. Es ist die Verantwortung des RAID-Controllers die Daten entsprechend auf die Platten zu verteilen und den entsprechenden Datenblock beim Lesen wieder herzustellen.
Die Effizienz einer RAID-0 Konfiguration für das Speichern großer Datenmengen hängt natürlich von dem jeweiligen Betriebssystem ab, das dafür verantwortlich ist die jeweiligen Lese- und Schreib-Befehle in die Übertragung von Blöcken von und zu dem RAID umzusetzen.
Während RAID-0 eine Lösung für das Problem des großen Speicherbedarfs darstellt, hilft es nicht die Fehlertoleranz des Plattenspeichers zu erhöhen.

Abbildung 1: RAID-0 Konfiguration
Redundanz mit RAID-1
Die notwendige Redundanz, um die Fehlertoleranz einer RAID Konfiguration zu erhöhen wird durch das Duplizieren von Daten auf zusätzlichen Plattenlaufwerken realisiert. Bei einer RAID-1 Konfiguration wird der gesamte Plattenbereich kopiert und man hat somit eine primäre und eine sekundäre Version der gespeicherten Daten.
Der RAID Controller ist dafür verantwortlich identische Versionen der Daten zu garantieren. Die Verteilung der Daten über die jeweiligen Sektoren und Stripes ist identisch zu RAID-0. RAID-1 hat jedoch den Vorteil, dass das Versagen eines Laufwerkes nur eine Kopie der Daten zerstört und man somit die Möglichkeit hat das defekte Laufwerk zu reparieren oder auszutauschen. Es müssen dann allerdings sofort alle Sektoren des fehlerhaften Laufwerks von dem funtionsfähigen Laufwerk kopiert werden, um eine neue Primär- oder Sekundär-Version der Daten wiederherzustellen.
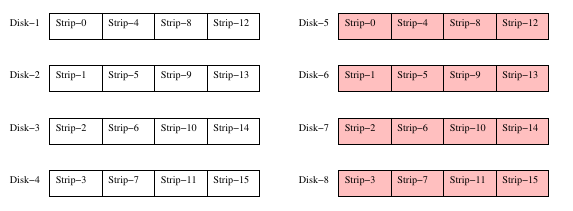
Abbildung 2: RAID-1 Konfiguration
Andere RAID Konfigurationen
Während RAID-1 die Fehlertoleranz des Plattenspeichers drastisch verbessert hat es den Systemdurchsatz, also die Performance, gegenüber RAID-0 nicht verändert. Um eine bessere Leistung des Plattenspeichers zu erzielen, speichert man die Daten in Worten anstatt in Streifen mit Sektoren, wie RAID-0 und RAID-1.
Zum Beispiel kann das RAID-2 die Daten in 4-Bit nibbles, oder halbe Bytes zerlegen und den jeweiligen Hamming Code
generieren. Somit werden die 4-Bit Daten in ein 7-Bit Wort umgewandelt, welches auf 7 verschiedenen Laufwerken abgelegt werden kann. Wenn man nun die 7 Laufwerke so synchronisiert, dass die zu einem Wort gehörenden Daten auf gleichen Zylindern liegen, können 7-Bit Bitmuster parallel geschrieben und gelesen werden. Eines der Nachteile dieser Konfiguration liegt darin, dass die Laufwerke synchronisiert sein müssen,
um die parallelen Eigenschaften des RAID-2 auszunutzen und den Durchsatz zu erhöhen.
RAID-3 ist eine vereinfachte Version des RAID-2, indem den Paritätsbits nur ein Laufwerk zugeordnet wird. Somit liegt zwar jedes der Datenbits auf einem unabhängigen Laufwerk, die Paritätsbits werden jedoch gemeinsam auf ein zusätzliches Laufwerk geschrieben. Mit diesem Ansatz reduziert man natürlich den Grad der Redundanz.
Die RAID Konfigurationen 4 und 5 stellen eine Erweiterung der RAID-0 und RAID-1 Konfigurationen dar, wobei nicht jedes Datenwort mit einem Paritätsbit abgesichert wird, wie in RAID-2 und RAID-3.
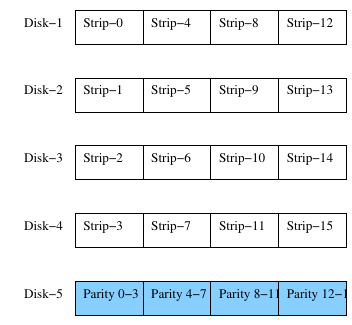
Abbildung 3: RAID-4 Konfiguration
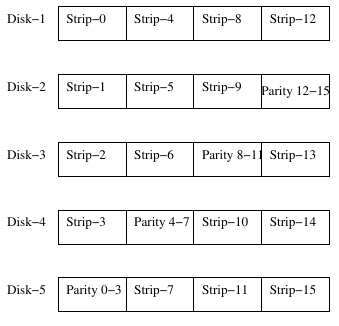
Abbildung 4: RAID-5 Konfiguration
In diesen Konfigurationen ist es nicht notwendig die Laufwerke zu synchronisieren, da hier, wie in RAID-0 und RAID-1, die Sektoren in die jeweilige Streifen auf einem Laufwerk geschrieben werden. Fehlertoleranz wird hier durch die Berechnung und Speicherung der Parität für alle Datenstreifen erzielt. Zum Beispiel, für Datenstreifen der Länge k wird die Parität der Streifen die auf die einzelnen Laufwerke verteilt sind, durch eine Exklusiv-Oder Funktion (XOR) berechnet. Damit ergibt sich ein Paritätsstreifen der Länge k der dann auf einem der Laufwerke gespeichert wird.
In RAID-5 wird dieser Paritätsstreifen über die existierenden Laufwerke verteilt. Während die RAID-4 Konfiguration gegen Datenverlust durch das Ausfallen eines Laufwerks Schutz bietet, hat es den Nachteil, dass es drastisch an Durchsatz verliert. Der Grund dafür ist, dass die Veränderung eines Sektors das Lesen aller Streifen erfordert, um die korrekte Parität zu berechnen.
In der RAID-4 Konfiguration muss auf das Paritätslaufwerk jedes mal zugegriffen werden, wenn Daten geschrieben werden. Somit kann dieses Laufwerk zu einem Flaschenhals werden, das den Durchsatz und somit die Effizienz des System verringert. RAID-5 wirkt diesem durch die gleichmäßige Verteilung der Paritätsstreifen über die verfügbaren Laufwerke entgegen.
Die Datenspeicherung mit RAID-Konfigurationen ist ein Beispiel für den Kompromiss, den man treffen muss, wenn Fehlertoleranz und Performance im System berücksichtigt werden müssen.
Du hast ein Upvote von mir bekommen, diese soll die Deutsche Community unterstützen. Wenn du mich unterstützten möchtest, dann sende mir eine Delegation. Egal wie klein die Unterstützung ist, Du hilfst damit der Community. DANKE!
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider supporting our funding proposal, approving our witness (@stem.witness) or delegating to the @stemsocial account (for some ROI).
Please consider using the STEMsocial app app and including @stemsocial as a beneficiary to get a stronger support.