Application of Data Mining Technology To Improve Students Academic Performance: Let's go practical with WEKA
INTRODUCTION
Today’s advancement in Information and Communication Technology has led to the electronic data collection and processing of data in various sectors, including educational settings. This electronic data is stored in database, as such, it contains hidden information for improvement of students academic performance, unfortunately, this hidden information can never be seen by ordinary naked eyes.
Predicting students academic performance for improvement in educational settings is highly important and encouraged, because it plays an important role in guiding and putting the students to the right track, especially towards making them excel in courses which turn out to be difficult to the past students.
However, the main problem jeopardizing this accomplishment is the lack of useful knowledge available for students in the ever increase amount of data stored in educational database. Indeed, the amount of data stored in educational database is increasing rapidly, this stored data if managed and used effectively, can turn out to be a big tool that could be used by the institution to produce great leaders of tomorrow and source of manpower for the country.

METHODOLOGY
The best methodology to consider in such a research work like this is to adopt the process of Data Mining techniques. It involves four (4)main steps: Data collection phase, pre-processing phase, classification phase, and interpretation / result & analysis phase.
In this study, the collected data will specifically be associated only with examinations records of the past students, hence several other related data may also be collected along, examples of such related data include student's entrance data such as Name, age, sex, parents address, contact number. e.tc. The overall activities are broadly categorized into the following steps:
- Data collection and Data set preparation.
- Data pre-processing.
- Data processing.
- Results & Analysis.
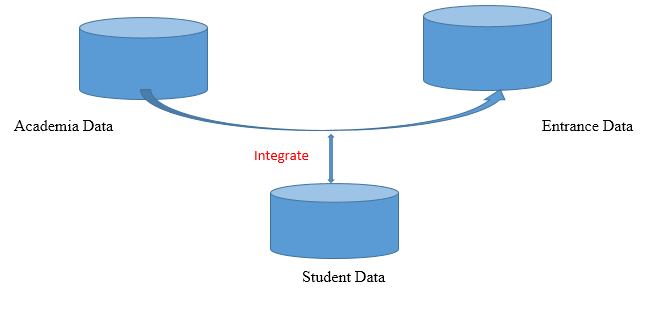
fig. 2. showing Data collection and Data set preparation phase. Image created by @noble-noah.
As shown in the figure 2. above, The data set may be obtained from any sample institution of learning. The data set must contain the Academia Data such as courses registered for, score, semester, matric number, attendance score, mid semester exam scores, main examination scores, total scores and grades and Entrance Data such as: Name, matric no., exam no, department, session, level, semester. This will be integrated to form Student Data as indicated in the figure above.
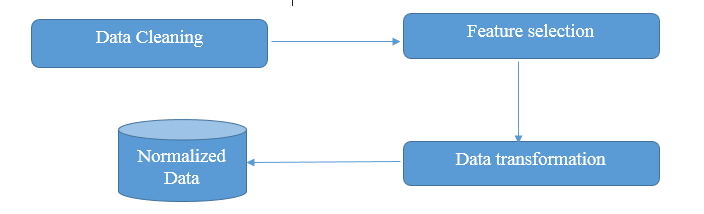
fig. 3. Data pre-processing phase. Image created by @noble-noah.
In this phase, the data collected and integrated will be prepared for processing. The data collected used to be huge and contains a lot of unwanted details, as such, there is a need to perform the second phase called 'pre-process phase', this involves data cleaning, feature selection and data transformation in order to prepare the data for the third phase. i.e processing phase.
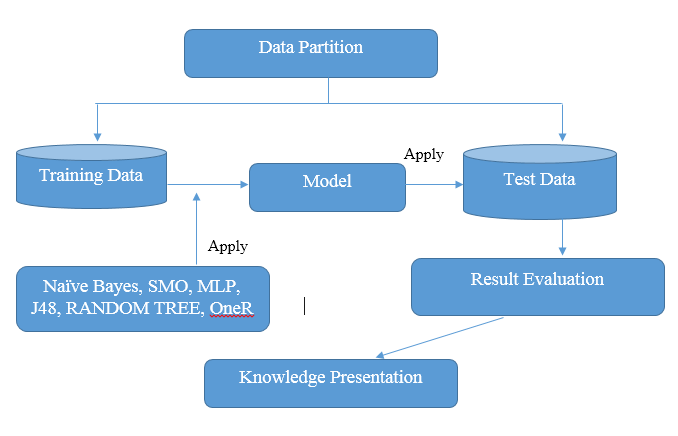
fig. 4. Data processing phase. Image created by @noble-noah
In this phase, the analyzer tries to predict some students academic performance through the help of data mining algorithms, of course, in educational data mining method, the most popular algorithm to predict students academics performance is classification. There are several algorithms under classification tasks that have been applied to predict students academics performance. Among the algorithms used are Artificial Neural Networks, K-Nearest Neighbor, Decision tree, Naive Bayes,and Support Vector Machine.
WEKA is considered as the analyzer tool here, because it is one of the notable known Machine learning software with many algorithms like the aforementioned algorithms above. It stands for Waikato Environment for Knowledge Analysis, it was developed at the University of Waikato, New Zealand.
These are the various benefit of the proposed approach which is as follows:-
- It provides many different algorithms for data mining and machine learning.
- It is open source and freely available, effective and efficient.
- It is platform-independent.
- It is easily useable by people who are not data mining specialists.
- It provides flexible facilities for scripting experiments.
- It has kept up-to-date, with new algorithms being added as they appear in the research literature.
Running the WEKA tool.
WEKA, being an open source and freely available software, therefore once the Weka tool is being run, the Weka GUI Chooser will pop up with different application on the platform.
Demonstration of classification rule process on dataset student.csv using j48 algorithm
- Step-1: We begin the experiment by loading the data (student.csv) into weka.
- Step2: Next we will select the “classify” tab and click “choose” button to select the “j48”classifier.
- Step3: Now we specify the various parameters. These can be specified by clicking in the text box to the right of the chose button. In this example, we accept the default values. The default version does perform some pruning but does not perform error pruning.
- Step4: Under the “text” options in the main panel. We will select the 10-fold cross validation as our evaluation approach. Since we don’t have separate evaluation data set, this is necessary to get a reasonable idea of accuracy of generated model.
- Step-5: We now click ”start” to generate the model .the Ascii version of the tree as well as evaluation statistic will appear in the right panel when the model construction is complete.
- Step-6: Now weka also lets us a view a graphical version of the classification tree. This can be done by right clicking the last result set and selecting “visualize tree” from the pop-up menu.
- Step-7: We will use our model to classify the new instances.
- Step-8: In the main panel under “text” options click the “supplied test set” radio button and then click the “set” button. This wills pop-up a window which will allow you to open the file containing test instances.
Expected result and Analysis: stage 4
Having carried out a study according to the approach stated above, a decision tree rule will be generated as stated in step 6. An instance of the tree is shown below along with decision rules
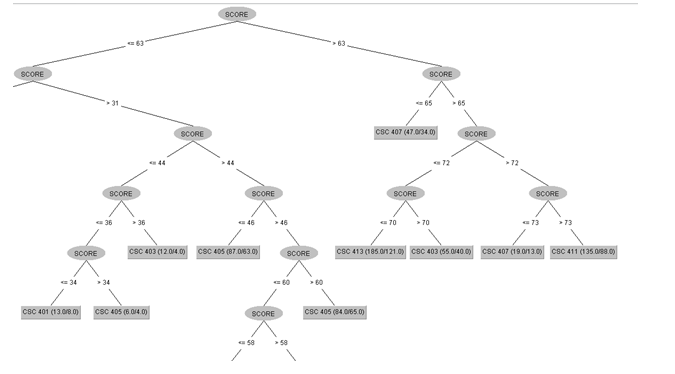
fig. 5. showing Decision tree Rule. Image created by @noble-noah.
Decision rules
Since the decision tree can be linearized into decision rules, where the outcome is the contents of the leaf node, and the conditions along the path form a conjunction in the if clause. In general, the rules are of the form: if (condition1 and condition2 and condition3) then outcome.
Based on the tree shown above, the rules show that:
- If Score is Greater than 73 then it is likely to be CSC 411
- If Score is Less than 70 then it is likely to be CSC 413
- If Score is Greater than 70 and Less than or Equal to 72 then it is likely to be CSC 403
- If Score is Less than or Equal to 73 and Greater than 65 then it is likely to be CSC 407
Conclussion
Applying Data Mining techniques in academic settings is mostly useful to help both the educators and learners improving their learning and teaching activities. cumulative grade point average (CGPA) and internal assessment as data sets are two most used attributes by the researchers. Whereas for prediction techniques, the classification method is frequently used in educational data mining settings. The most used classification techniques algorithms are Neural Network and Decision Tree.
In conclusion, the meta-analysis on predicting students performance as discussed above should motivate us to carry out further research to be applied in our environment. It will help the educational system to monitor the students’ performance in a systematic way.
Final remarks!
Based on the importance of applying Data Mining techniques in our academic settings as discussed above, I hereby recommend that universities should begin to use data mining algorithm for collation of large amount of data and to predict the performance of students. I also recommend that it should also be introduced to secondary school to determine the area where they (the students) best fit into e.g. commercial class, art class, and science class.
Thanks for reading through!
References
[1] Alao, D. and Adeyemo, A. B. (2013). ANALYZING EMPLOYEE ATTRITION USING DECISION TREE ALGORITHMS. Computing, Information Systems & Development Informatics Vol. 4 No. 1 March, 2013. Download here
[2] Anoopkumar, M., & Rahman, A. M. J. M. Z. (2016). A Review on Data Mining techniques and factors used in Educational Data Mining to predict student amelioration. In 2016 International Conference on Data Mining and Advanced Computing (SAPIENCE), (pp. 122–133). Downlod here
[3] A. M Shahiria, W. Husaina & N. A Rashida (2015). A Review on Predicting Student’s Performance using Data Mining Techniques. Procedia Computer Science 72 ( 2015 ) 414 – 422. Download here
[4] I.A Ganiyu & I.O Awoyelu (2015) “Job Opportunity Factors Analysis Using Decision Tree Algorithms” Computing, Information Systems, Development Informatics & Allied Research Journal Vol. 6 No. 4, December, 2015. pp. 59-66. Download here.
[5] I.A Ganiyu. (2016) “Data Mining: A Prediction for Academic Performance Improvement of Science Students using Classification” International Journal of Information and Communication Technology Volume 6 No. 4, April 2016. Download here.
[6] H. SHARMA & S. KUMAR (2017) “PREDICTION OF MU STUDENT’S PERFORMANCE USING DATA MINING TECHNIQUE” International Journal of Computer Science and Mobile Computing, Vol.6 Issue.5, May- 2017, pg. 405-417. Download here
This post has been manually curated by @bhattg from Indiaunited community. Join us on our Discord Server.
Do you know that you can earn a passive income by delegating to @indiaunited. We share 80 % of the curation rewards with the delegators.
Here are some handy links for delegations: 100HP, 250HP, 500HP, 1000HP.
Read our latest announcement post to get more information.
Please contribute to the community by upvoting this comment and posts made by @indiaunited.
Your publication has been voted by Edu-Venezuela. It will carry over to other curation projects to get more voting support. Keep up the good work!
Thanks a lot, I appreciate!
Data mining will help Education Institution to better understand student performance so that they can come up with better policies. !discovery 15
Exactly @juecoree . Happy to read your feedback!
This post was shared and voted inside the discord by the curators team of discovery-it
Join our community! hive-193212
Discovery-it is also a Witness, vote for us here
Delegate to us for passive income. Check our 80% fee-back Program
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider supporting our funding proposal, approving our witness (@stem.witness) or delegating to the @stemsocial account (for some ROI).
Please consider using the STEMsocial app app and including @stemsocial as a beneficiary to get a stronger support.