Research diaries #16: Reservoir computing, an AI which does not live inside a computer
In this post we will look at a fancy AI called reservoir computing. We will just be looking at the general concept. In a future post I will show you an implementation of this fancy neural net.
By now we probably all have played around with AIs like ChatGPT, DALLE. But how do you actually create an AI. The majority of AIs are neural net based training these neural nets to generate text or images is a computationally intensive task. A neural net is like a very general model with many possible configurations. The vast majority of these configurations are nonsensical. So the game is to somehow find a model which performs well on the task you want it to do. That is not to say that selecting a neural net is an easy problem. Indeed there are two problems, selecting or building a neural net and then training the neural net to perform well on the task.
The majority of neural nets have some kind of nested structure where the input information gets transformed many times before it ends up at an output. Here input can be read for example as the question you ask ChatGPT and output as the text it generates. At each transformation there are parameters which need to be suitably chosen when finding a good model for the task. Due to this nested structure finding good parameters is a heavy computational task.
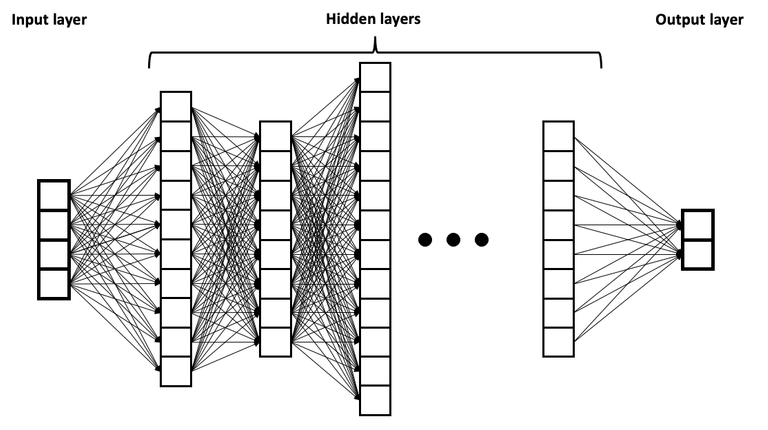
The trainable components are sequentially stacked in connected layers
CC Attribution share alike 4.0
Simple image classification like telling cats apart from dogs you can do on a home computer but for the real-world tasks you need something much bigger. Nowadays we are at a stage where complicated models can only be deployed by big institutions or companies as even universities do not have the resources to get the necessary equipment.
Hence, effort has been made to develop methods which can deploy networks with less computational resources. The first thing that comes to mind is the unnatural way we try to find the optimized model. The computations that we do on a computer are not really the exact computations we need to perform. The operations are not hard encoded in the hardware. Consequently, it seems fruitful to develop hardware that exactly does the computations that are needed to find the optimal parameters.
A completely out of the box approach to this problem is reservoir computing. Remember how neural nets are generally a kind of nested transformation. This is because this nestedness introduces some nonlinearity in the system. This nonlinearity is needed because difficult tasks are generally not linear. So we could make the assumption that nonlinearity is much more important than these trainable parameters within these nested transformation. This leads us to the general framework for reservoir computing. We have the input information flowing into a reservoir of nonlinear process without trainable components which flows into a few trainable parameters which then give the output.
The interesting thing about the reservoir is that real physical systems can be reservoirs as long as they are in a sense nonlinear enough. For example buckets of water under suitable conditions can be a reservoir as the underlying motion is nonlinear enough. There are of course many caveats here. Nonlinear enough is definitely not satisfied by any system and I think it is unlikely that this framework will work for very complicated tasks like the ones I was talking about in the beginning. It is generally a good framework where the process is simple enough that implementing it on a computer is overkill.

The reservoir looks like a chaotic mess in comparison to the previous neural net
By Herbert Jaeger CC BY-SA 3.0
{kind=link}
That's all for now. In a future post we will look at an implementation and uncover the underlying dynamics of the reservoir.
Reference: Nakajima, Kohei. "Physical reservoir computing—an introductory perspective." Japanese Journal of Applied Physics 59.6 (2020): 060501.
My cat didn't like snow enough to take a photo tax

Congratulations!
✅ Good job. Your post has been appreciated and has received support from CHESS BROTHERS ♔ 💪
♟ We invite you to use our hashtag #chessbrothers and learn more about us.
♟♟ You can also reach us on our Discord server and promote your posts there.
♟♟♟ Consider joining our curation trail so we work as a team and you get rewards automatically.
♞♟ Check out our @chessbrotherspro account to learn about the curation process carried out daily by our team.
🏅 If you want to earn profits with your HP delegation and support our project, we invite you to join the Master Investor plan. Here you can learn how to do it.
Kindly
The CHESS BROTHERS team
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.
Ideas for Tarantino's last movie, I guess...
which movie is that 👀
Well his 'first' movie was Reservoir Dogs. His next movie is supposed to be his last one, that's what he's saying, so I guess he could name it Reservoir Computing, completing a sort of cycle! :D
Congratulations @mathowl! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 4000 comments.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out our last posts:
Support the HiveBuzz project. Vote for our proposal!