Using Python & Pandas' read_html() Function To Scrape Football Tables
Hi there. In this post, I cover basic web scraping with the use of Python and the read_html() function from the Pandas package. I show how to use read_html() to extract football league tables from websites. I use football instead of soccer here. The motivation behind this post was from discovering read_html() from a Data Professor youtube video.
La Liga and Bundesliga football table data were obtained on January 19, 2022 and January 20, 2022 for the Premier League Table.

{kind=link}
La Liga Spanish Football League Table
Obtaining the La Liga Spanish football table is not too difficult. I used the Skysports La Liga Table link to extract the table. It was not possible to use read_html() on the official La Liga website.
import pandas as pd
# SkySports La Liga table, unable to do from La Liga Satander website
laliga_url = "https://www.skysports.com/la-liga-table"
liga_df = pd.read_html(laliga_url , header = 0)
laliga_df = liga_df[0]
# Nicely formatted table:
laliga_df
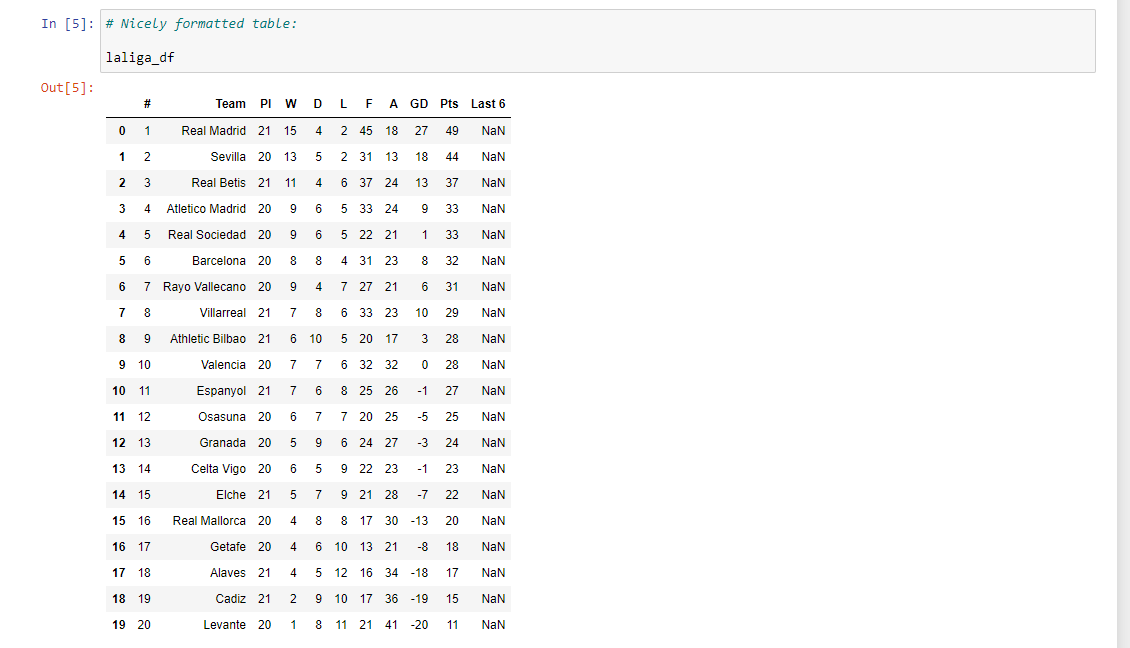
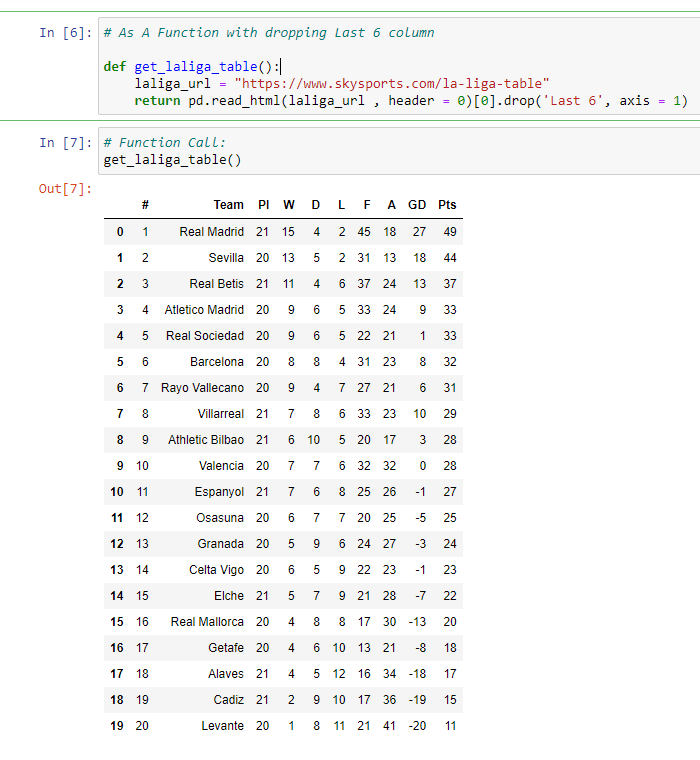
I have also combined the above code into a function. There is an additional part which removes the Last 6 column with all the NaN values. NaN means not a number.
# As A Function with dropping Last 6 column
def get_laliga_table():
laliga_url = "https://www.skysports.com/la-liga-table"
return pd.read_html(laliga_url , header = 0)[0].drop('Last 6', axis = 1)
# Function Call:
get_laliga_table()
Bundesliga German Football Table
The Bundesliga table is from the official website. Extracting the German football table is easy with the use of read_html(). The data cleaning part takes a bit of time though.
bl_url = 'https://www.bundesliga.com/en/bundesliga/table'
bundes_df = pd.read_html(bl_url, header = 0)
df = bundes_df[0]
# Remove Unnamed columns 0, 2, 3 and 5:
df1 = df.drop(['Unnamed: 0', 'Unnamed: 2', 'Unnamed: 3', 'Unnamed: 5'], axis=1)
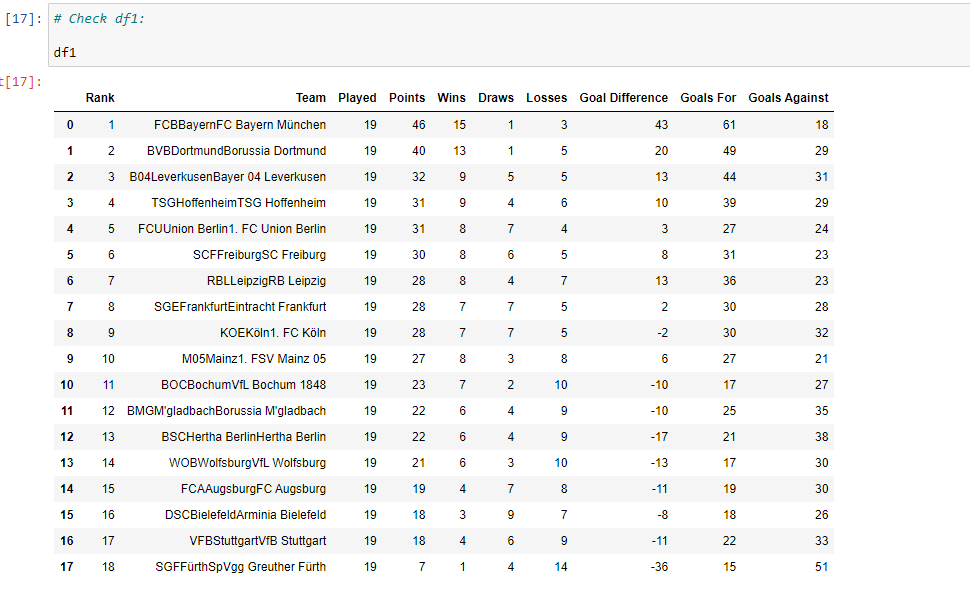
# Check table now
df1
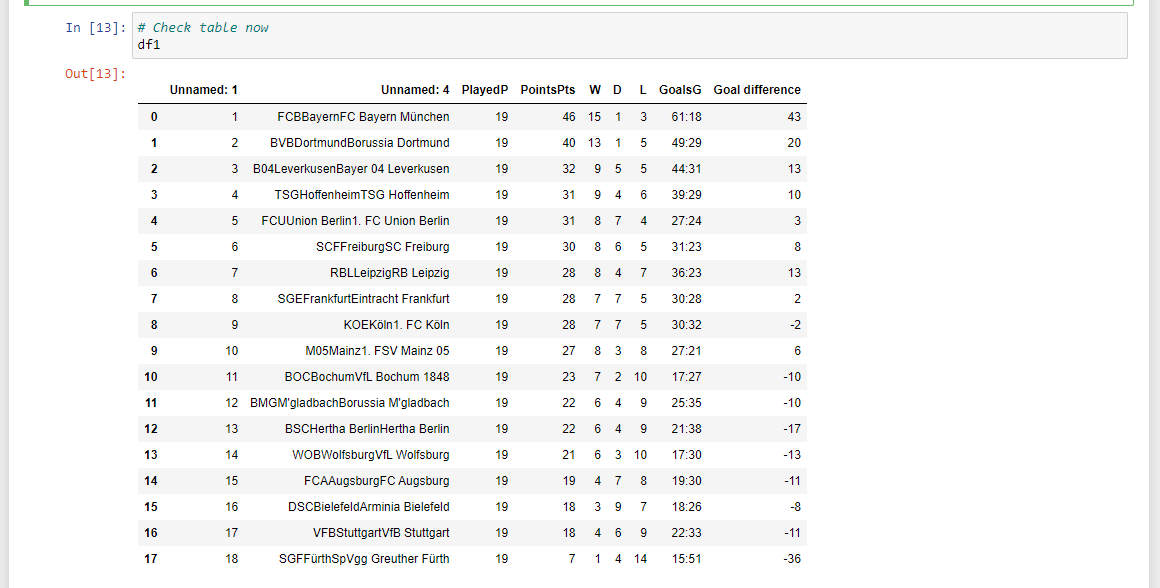
We have the Goals Difference and Goals in the form of Goals For:Goal Against Ratio style format. I wanted to split this into two separate columns with the colon : sign.
I create two new columns which are Goals For and Goals Against. I use the split method on the Goals G column to separate them by the colon sign.
# Split GoalsG column into Goals For & Goals Against columns:
# https://cmdlinetips.com/2018/11/how-to-split-a-text-column-in-pandas/
df1[['Goals For','Goals Against']] = df1['Goals G'].str.split(":",expand=True,)
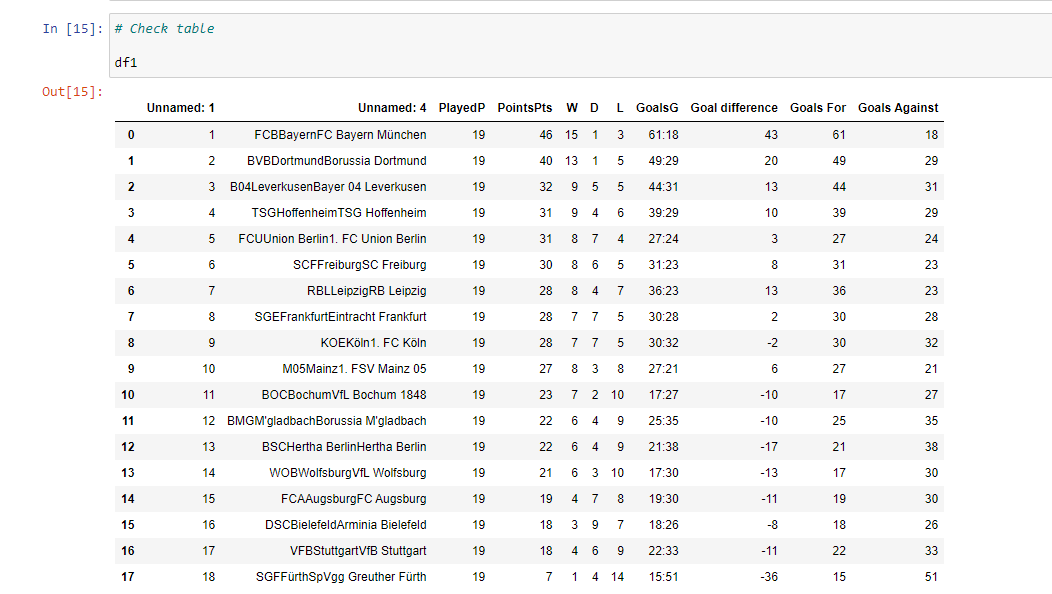
I drop the Goals G column and rename the columns. The Team names have not been fixed as I have not found a solution for that column.
# Remove GoalsG column and rename columns:
df1 = df1.drop('Goals G', 1)
df1.columns = ['Rank', "Team", 'Played', 'Points', 'Wins', "Draws", "Losses", "Goal Difference", 'Goals For', 'Goals Against']
Like with the La Liga football table code, I have combined the code here into one function. No function call output shown here.
# Create Function in obtaining Bundesliga table (all the above code together):
def obtain_bundesliga_table():
bl_url = 'https://www.bundesliga.com/en/bundesliga/table'
bundes_df = pd.read_html(bl_url, header = 0)
# Obtain table
df = bundes_df[0]
# Remove Unnamed columns 0, 2, 3 and 5:
df1 = df.drop(['Unnamed: 0', 'Unnamed: 2', 'Unnamed: 3', 'Unnamed: 5'], axis=1)
# Split GoalsG column into Goals For & Goals Against columns:
df1[['Goals For','Goals Against']] = df1['Goals G'].str.split(":",expand=True,)
# Remove GoalsG column and rename columns:
df1 = df1.drop('Goals G', 1)
df1.columns = ['Rank', "Team", 'Played', 'Points', 'Wins', "Draws", "Losses",
"Goal Difference", 'Goals For', 'Goals Against']
return df1
English Premier League Football Table
Obtaining the English Premier League football table is not too bad. You would use pandas read_html() function directly with a provided link.
# Take current Premier League table
epl_url = "https://www.premierleague.com/tables"
# Read in table with pandas read_html
df = pd.read_html(epl_url, header = 0)
epl_df = df[0]
If you check the dataframe (output not shown) you will find that you do not need every other row. Using pandas .iloc allows for filtering and extracting the parts of the dataset you need.
# Obtain the rows needed with iloc. Every other row not needed.
epl_df = epl_df.iloc[0:len(epl_df):2, :]
epl_df
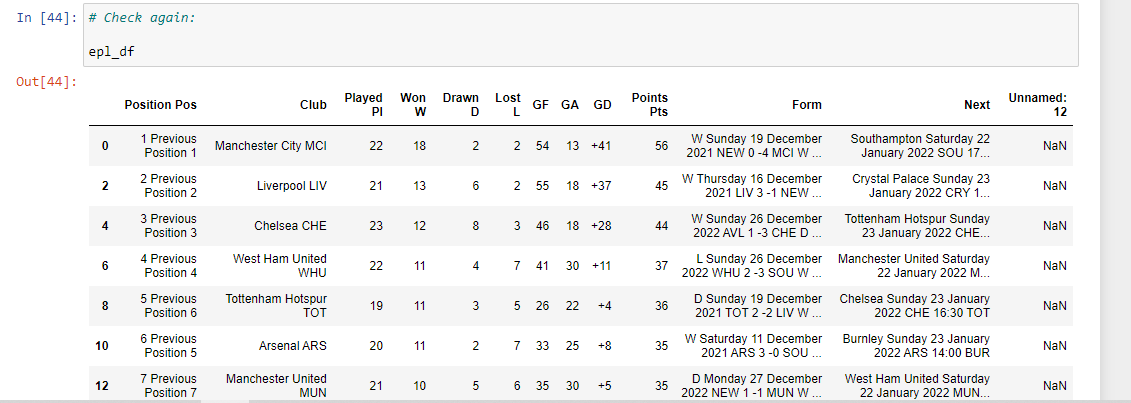
The Unnamed:12 column can be removed with the use of .drop().
# Drop Unnamed:12 column:
epl_df = epl_df.drop('Unnamed: 12', axis = 1)
Under the Position Pos column, there is too much text. All you need is the position number. I use the following code chunk to extract just the rank number for the team.
# Extract rank number in Position Pos column:
# Reference: https://stackoverflow.com/questions/36505847/substring-of-an-entire-column-in-pandas-dataframe
epl_df['Position Pos'] = epl_df['Position Pos'].astype(str).str.slice(0,2)
For the full code for the Premier League tables here it is:
# Put it all together as a function:
def print_epl_table():
epl_url = "https://www.premierleague.com/tables"
epl_df = pd.read_html(epl_url, header = 0)[0]
# Remove every other row
epl_df = epl_df.iloc[0:len(epl_df):2, :]
# Drop Unnamed:12 column:
epl_df = epl_df.drop('Unnamed: 12', axis = 1)
# Extract rank number in Position Pos column:
epl_df['Position Pos'] = epl_df['Position Pos'].astype(str).str.slice(0,2)
return epl_df
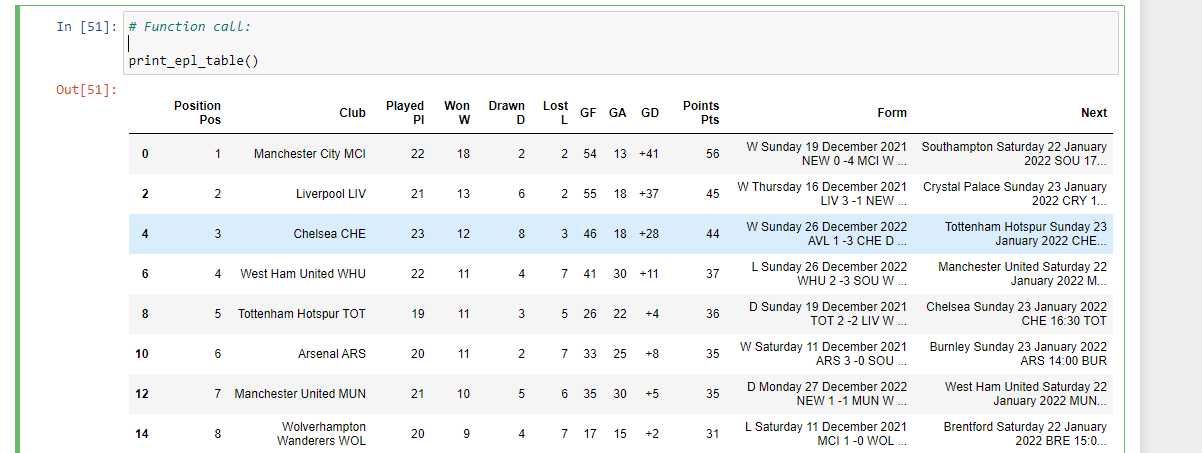
# Function call:
print_epl_table()
Partial table screenshot shown here as of January 20, 2022.

{kind=link}