Building a case for IPFS - SPK Network as a Game Changer.
In the traditional web architecture, user data is stored on centralized storage serves, which are owned, governed, and controlled by centralized companies, hence implying one point of failure. This control provides them elevated privileges that could be abused at the expense of the end/user. It wouldn't be the first time big companies leaked the data, so we're not talking game theory, rather something that happens every few months. lol

Going further, a single point of failure could be misused by the governments to disable access to the internet to the entire nation. Yet again, we're not speculating game theory, it happened to Egypt during the January revolution, whereby Mubarak saw himself entitled to pull the plug and kill the thing feeding protestors.
Moreover, there are technical limitations to HTTPS/HTTP due to their centralized nature. Not only it's possible to delete, remove or censor content, but it's also actually easy to congest the network by creating a bottleneck on the main server. DDoS is quite a popular technique, used to sabotage the performance of the centralized network.
But How Exactly Does it Work?
To understand why IPFS matters it's important to understand the technical background of current protocols that are governing the web.
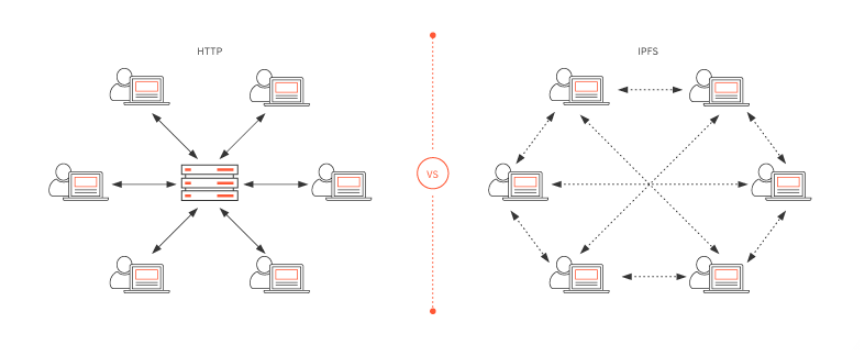
The web uses location-based addressing to store and retrieve files. Let’s say we want to access a cat picture cat.png from domain abc.com. We’ll access this location (i.e abc.com/cat.png) via a web browser and in return, we’ll get the cat picture. If however, the file has now been removed from the abc servers for whatever reason, we won’t be able to access the picture anymore. Now there is a possibility that someone else on the internet has a copy of that same cat picture, but we have no way of connecting with them and grabbing a copy of that picture. A lot of files on the internet may have the same name but the contents will likely be different.
When you want to visit a website, your client (browser) sends a request to the servers that have the data you're looking for, even though the server could be stationed on a completely different continent. This is something called location-based addressing. The problem is that the information can travel as fast as the speed of light, meaning that physical limitations play a role as well.
Now imagine if million people simultaneously requested the same document...
This process eats a lot of energy, bandwidth, and costs a fortune.
From here the idea of distributed file system came to life. IPFS solves this problem.
IPFS
IPFS stands for the interplanetary file system. It's a peer-to-peer open-source protocol for file storage that uses content-based addressing, rather than location-based addressing. This means that in order to track the file/document, we don't need to know where it is, rather what it contains. Every file has a Hash function that cannot be separated from the content it is relative to. That's how @threespeak plans to utilize the #Hive blockchain.
Hash function creates a unique fingerprint for every file. So if we want to retrieve a file, we’ll ask the network “who has this file (QmSNssW5a9S3KV...)”, and then someone from the IPFS network who has it will provide it to us. We can verify the integrity of the file by comparing the hash of what we requested against what we received, and if the hashes match, then we know that the file hasn’t been changed. This hash function also helps de-duplicate the network, such that no file with the same content can be submitted twice since the same content yields the same hash. This optimizes storage requirements and also improves the performance of the network.
IPFS basically works by connecting all devices on the network to the same file structure.
IPFS should be used to store only relevant and important files, that are marked and determined by pinning, whilst irrelevant information should be removed by the garbage collectors.
This way, the protocol sustains its storage, by simply eliminating data that only eats the space.
LIMITATIONS
Like with every technology, IPFS has some challenges to solve before going mainstream.
TO begin with, one of the biggest issues is keeping the files available.
When you pin data on the IPFS node, you are telling that node that the content is relevant, thus shouldn't be deleted by the garble collectors. "Pinning" actually prevents important data to be deleted permanently. However, the problem is that you can only pin the data on your node.
You cannot force other nodes to pin the data for you, so to be sure your content stays pinned, you have to run your own IPFS node.
Going further, there's one more awkward situation where you have to use a traditional communication mechanism to find someone who has the file. I ass

Another limitation is the actual sharing of files. You have to share a file link (content address) with someone else on the network via a traditional communication mechanism, say an instant message, email, Skype, Slack, etc. This means file sharing is not built into the system. People have developed crawlers and search engines the network, but it will likely take some time before it all catches on.
Search engines will have to be built on top of the #SPK network in order to make it as easy for the end-users to get along with this new system - and it'll be worth it.
Information weights more value than any other physical property, therefore, something like the #SPK network will save the world's most important knowledge, and that's powerful!
IPFS needed blockchain tech to wrap everything up in a coherent and trustless system.
Tokenomics, Governance, and IPFS will be the game-changer.
We're taking back what's been stolen from us!
Posted Using LeoFinance Beta
I've not heard of #SPK, and still trying to wrap my head around Merkle trees, But I'm super impressed by IPFS!
I think projects like The Graph are also super important in speeding up adoption and making IPFS more user friendly.
Posted Using LeoFinance Beta
IPFS will be huge if it manages to attract critical mass... Otherwise, it'll be pointless...
Graph is fucking awesome!
This is so much to work around, it is amazing that the SPK team has been able to get so far, this is one monumental breakthrough that we are yet to understand the value it brings, i perceive that so much other developments will come from this than what it is presently. Everything going well, SPK will indeed be a game changer
Posted Using LeoFinance Beta
Terrific piece. You are right, there is a lot to build out. It is vital that we look at things from the long term perspective. It is only recently that the issue with censorship because so blatantly obvious. Now, there are steps being taken to combat that. It will take some time, especially for this system to even begin to rival what is in place. A lot of infrastructure needs to be built out.
Posted Using LeoFinance Beta
Ye, I just hope the market will appreciate the effort and tech behind it.
Your post was promoted by @taskmaster4450le
Sorry not making a comment relating to the topic.
But did you do the art work yourself?? :D Because thats amazing!
Hahaha it's not mine, I'm actually retarded for art, forgot to put the source. 😂😂
Ohh. Haha
Its just really amazing! :D