Sportstalksocial 50% author rewards tax for non-native posts proposal - DATA analysis to see if it is necessary .
Good evening to everyone . I hope you are having a good day .
Recently a lot is happening on LeoFinance , we all are very excited about the upcoming airdrops , #projectblank etc but the thing is a lot is happening on other tribes too . One such example is SportsTalkSocial moving to Archon type of governance system which was passed last week . Post link
SportsTalkSocial Proposals
Yesterday @patrickulrich posted another proposal which is 'Proposal to adopt reward change' .
I saw a few users actually having doubts about this - whether it is necessary or not . So I decide to gather some data from HiveSQL regarding posts , tags and see if I can provide info to users to let them make their decisions . It is always good to make informed decisions isn't it?
Code - Please double check this .
I am going to post the code I used to gather the data - I will explain it but I will request @patrickulrich to get someone he trusts to check if the data / codes are correct and accurate .
Note- I am using 30 days posts data , not the entire history of posts made on sportstalksocial as it doesn't make sense to me . Most recent data is sufficient to make the decision so I have gathered the data for past 30 days
Tagging @geekgirl since she knows HiveSQL and python, to help me . I don't wanna mess this up and give wrong info .
Coming to the codes -
import pyodbc
import json
import pandas as pd
conn = pyodbc.connect('Driver={SQL Server};'
'Server=vip.hivesql.io;'
'Database=DBHive;'
'uid=Hive-amr008;'
'pwd=--hidden--;'
'Trusted_Connection=no;')
cursor = conn.cursor()
I have used the above code to connect to HiveSQL . It is not necessary with respect to SportsTalkSocial . The below codes are necessary
Last 30 days posts data -
sports_native = pd.read_sql_query(''' select * from TxComments where timestamp > GETDATE()-30 ORDER BY ID DESC ''',conn)
So I am just storing all posts details in sports_native Dataframe which looks like this -
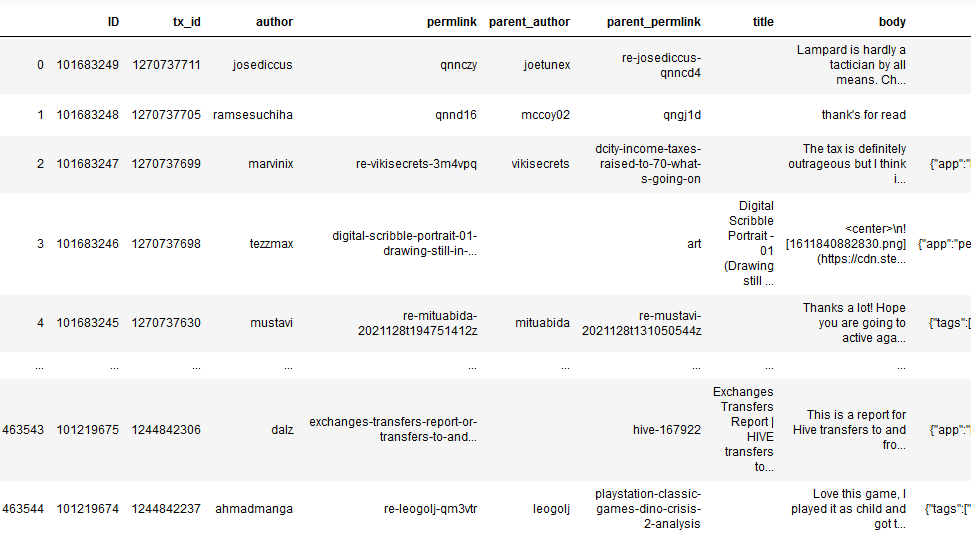
It took 45 minutes for me to just gather 30 days of posting details . Anyway moving forward , important codes -
app_list=[] # Using the list to store the 'front_end' through which posts are authored.
for i in range(0,len(sports_native)):
try:
if(sports_native['parent_author'][i]==''): # Means I am taking only posts and not comments
json_posts=json.loads(sports_native['json_metadata'][i])
if 'tags' in json_posts:
if 'sportstalk' in (json_posts['tags']): # If the tags contain 'sportstalk' in it or is directly posted to 'hive-101690' which is SportsTalkSocial community.
if 'app' in json_posts:
app_list.append(json_posts['app']) # Then store the 'front-end' used in the app_list.
except:
print("EXCEPT block entered:"+str(i))
pass
The above code is pretty simple - These are the steps I have followed
- Check if it is a post or comment - Take only posts and neglect comments
- Check if the tags contain 'sportstalk' or directly posted to 'hive-101690' which is 'SportsTalkSocial' community . ( only then it is displayed in sportstalksocial front-end)
- If 2 is yes , store the 'front-end' used to post in app_list .
I hope this much is clear .
Now if I print app_list - this is the output -
The above image is just a sample , it contains more rows .
Now if it has been posted through SportsTalkSocial front-end , then we will save 'sportstalksocial/0.1' as 'app' ( front-end )
sports_native_count=0
non_native_count=0
for i in range(0,len(app_list)):
if(str(app_list[i]).startswith('sportstalksocial')):
sports_native_count += 1
else:
non_native_count += 1
print("Sportstalk Native posts count:" +str(sports_native_count)+", Sportstalk non native post count:"+str(non_native_count))
What have I done in the above code?
- I have searched if the front-end starts with 'sportstalksocial' - if yes I have +1'd the sports_native_count .
- If 1 is wrong - that means the front-end was something other than 'sportstalksocial' - then I have +1'd the non_native_count .
Want to know the results ? This is the result -
Sportstalk Native posts count:575, Sportstalk non native post count:8940
Proportion representation in Pie Chart
To all those who just skipped the above part because it was too nerdy , lol , you can look at this pie chart -
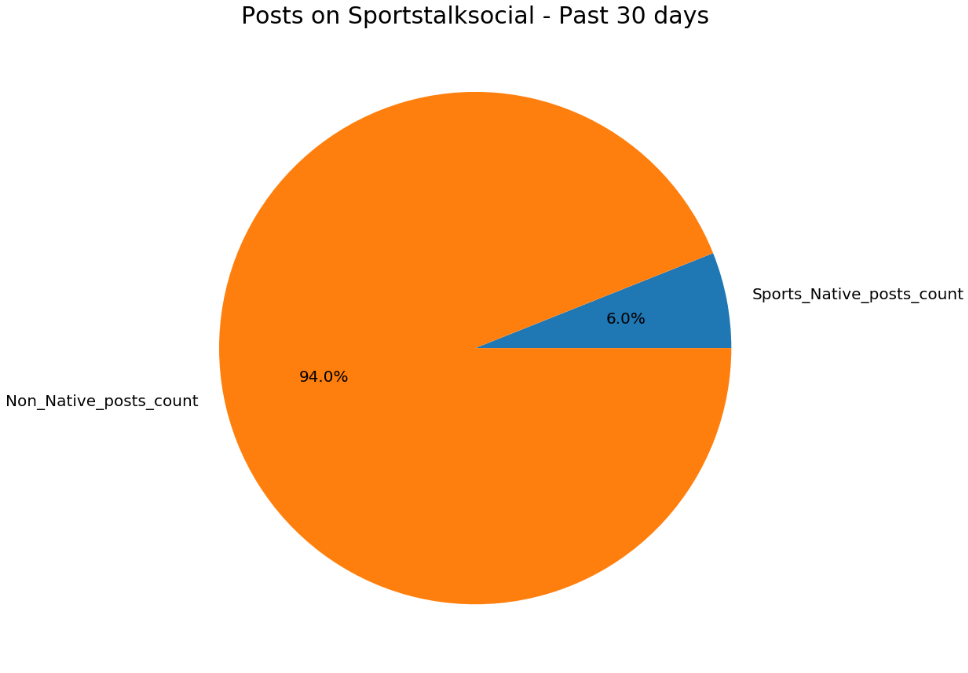
I won't comment on the above chart .
Note
Must read-
I have to confess that I did this program in a hurry ( because only 4 days remaining to vote on proposal) and that is why I want @patrickulrich to double check this or anyone familiar with HiveSQL to cross-check .
This data is purely for posts and not comments , this is the most important part . I have extracted the data for only posts ( past 30 days ) and not comments , when comments is factored in the data may worsen or favor 'Native posting' which I cannot guarantee.
The data is only for past 30 days - that is between 29th December to 28th January ( today ) . If you consider older data ( which I don't suggest because recent posting data gives a better picture ) then the stats might change .
I am not trying to influence anyone's decision but I always believe that people should make informed decision .
That's it from me today . I hope this post gave you some king of insight before voting for the proposal .
Regards,
MR.
Posted Using LeoFinance Beta
That pie chart is not surprising at all. Consider a high percentage of all posts come via actifit this makes sense. I know I post from Peakd as I do prefer it.
Posted Using LeoFinance Beta
True , couple of weeks ago I posted that too - Actifit vs Other-posts on Sportstalksocial and almost 70% of them were actifit .
What is your take on the 50% tax on non-native proposal?
Posted Using LeoFinance Beta
I think it will make a difference and it will also stabalise sports token price. Less being earned by posts that possibly shouldn't be earning that many.
Posted Using LeoFinance Beta
You are right . It will not eliminate indiscriminate dumping of SPORTS but this proposal will reduce the amount dumped to great extent is what I think.
Posted Using LeoFinance Beta
Shit, that was a lot of posts from not Sportstalk :)
Nice that you tries to bring data to the discussion
Yes :( unfortunately .
Thank you :)
Posted Using LeoFinance Beta
There are so many tokens on hive-engine and the ones that will outperform is difficult to pick. If I recall correctly I had these sports tokens but sold them a long time ago and bought the PAL token for it..Cheers
You are right about numerous tokens but I feel SPORTS really has the potential to reach higher heights because it is the one topic which all countries love.
Posted Using LeoFinance Beta
I'm expecting you to make some serious and consistent data digging for SportsTalkSocial maybe on weekly basis. This looks cool already.
I am ready to do it :) I love it and if you ever need any data similar to above , let me know I will get it ASAP.
Posted Using LeoFinance Beta
Code looks correct, although I'm sure SQL would do the job in less than 30 mins!
Hey @abh12345.stem . I used HiveSQL itself for the data , might be my internet sucks not sure and thanks for cross checking .