RE: Using HiveSQL with Python on Mac
You are viewing a single comment's thread:
That's what troubled me too, I asked the same on discord couple of weeks ago and got this answer
There is a bug in Keychain where some transactions are broadcasted twice. I guess this is something related to that. Even though two custom jsons were processed at the same time, Hive Engine would have accepted only one.
Then I headed down to Hive Engine explorer and saw this

First image ( accepted stake )
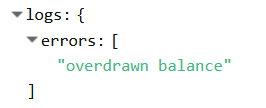
Second image ( rejected stake )

So the payload for both the custom_json was the same but the 'logs' was different . So if you want reliable 2nd layer token JSON data , according to me , hiveengine API is where to look at.
HiveSQL stores 'payload' in its table but what we need here is actually 'logs' . So right now I am extracting all the data from December 1st and storing it in JSON format ( although I prefer CSV , it will become difficult for me to clean it later) .
Did any of the above make sense?
!WINE
Posted Using LeoFinance Beta
Cheers, @amr008 You Successfully Shared 0.100 WINE With @geekgirl.
You Earned 0.100 WINE As Curation Reward.
You Utilized 2/3 Successful Calls.
WINE Current Market Price : 0.000 HIVE
Yes, everything makes sense. I looked at some examples. You are right, there is no way to see which one is rejected, or accepted in HiveSQL.
The question is if 'logs' is actually stored in the blockchain or is it probably stored in a separate hive-engine database?
Hm that's the question I am trying to find answer too. I would love to work with HiveSQL itself because via API it takes a lot of time.
Posted Using LeoFinance Beta
I don’t know if this will help, but one idea is to collect all transaction_ids where logs show ‘error’ from hive-engine api. Then use this list to exclude in HiveSQL query.
For sure that can be done but as far as I have explored till now , you can get the logs data only by going through all the blocks one by one.
Using a for loop , right now it's fetching 1000 blocks in 4 minutes so yeah it takes a long time again.
custom_json are non-consensus operations. This means that the blockchain will never reject any (except if authorities are missing).
Therefore, HiveSQL (like the blockchain) includes all broadcasted custom_json, even if "duplicate" or considered as invalid by a 2nd layer app.
This is why there is no hive-engine "state" table in HiveSQL because the hive-engine code is closed source and HiveSQL doesn't know how to interpret those operations.
Got it :) Thanks for taking your time and clearing it.
Thank you @arcange for explaining.
My pleasure.