Node Red and Grafana
Node Red is a really good, open source, flow-based data manipulation tool. It excels at connection to API's, pulling data, manipulating it, and sending it to an output. It has dashboarding abilities, much like the one I use for monitoring the speed of my home internet connection but, frankly, it's dashboards are rather simplistic.
Grafana, on the other hand, is a superb, open source, dashboarding utilities. Just like Node Red is used to connect to API's, Grafana is used to connect to data sources and present the data in really smart ways. The right tool for the right job, so to speak.
Node Red and Grafana work really well together; Node Red to collect data, and Grafana to present it in a dashboard. In this example I'll use Node Red to connect to the coingecko.com API to pull the most recent USD price for a number of coins, store the results in a local database, and then use Grafana to view the data in a nice looking dashboard.
MySQL Database
Table 1: Coin Names
|-|-|
Field|Type
coin_id|integer
coin_name|text
coin_api|text
The "coin_api" field is the name of the coin that CoinGecko needs in it's API query.
Table 2: Coin Values
|-|-|
Field|Type
coin_id|integer
value|float
timestamp|timestamp
Note that between the two tables the only shared field is the "coin_id" field. If I want to see the value of a coin by name I will need to perform an SQL join. This is preferable so as to not duplicate data. For a database this size there isn't much of an issue, but if my database had dozens of tables with millions of rows, duplicate data causes data size bloat.
If you're interested, here are the coins I'm pulling data for:
MariaDB [coins]> SELECT * FROM coin_names;
+---------+-----------------------+-----------------------+
| coin_id | coin_name | coin_api |
+---------+-----------------------+-----------------------+
| 1 | Doge Coin | dogecoin |
| 2 | Hive | hive |
| 4 | Steem | steem |
| 5 | Basic Attention Token | basic-attention-token |
| 6 | Bitcoin Cash | bitcoin-cash |
| 7 | Blurt | blurt |
| 8 | Presearch | presearch |
| 9 | Appics | appics |
+---------+-----------------------+-----------------------+
Node Red Flow
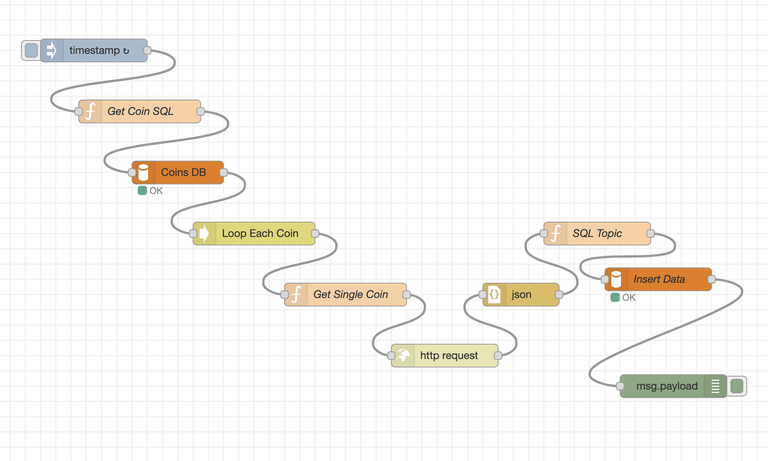
Without getting into too much detail on the inner workings of this flow, I've named each 'block' in the path with a label that should explain what it does.
- Get Coin SQL: Builds the SQL to retrieve the list of coins I am interested in from my local mysql database.
- Coins DB: This block takes the qperforms the actual query against the local mysql database and returns the results.
- Loop Each Coin: I don't want to create a new set of flows for each coin, so instead I'm looping through each one. Essentially, "Do the first, then the second, then the third, etc."
- Get Single Coin: Takes the coin output from the previous step to pass it to the next block.
- "http request": This performs the http query against the coingecko api. If you're interested, the query looks like this:
https://api.coingecko.com/api/v3/simple/price?ids={{{payload}}}&vs_currencies=usd - "json": Convert the output to a javascript json object that Node Red can manipulate.
- SQL Topic: This formats the SQL INSERT statement that will insert the data into the coin_values table.
- Insert Data: Performs the actual SQL insert.
- msg.payload: simple debug to ensure all is well.
Grafana
I have Grafana running on the same server. It's a desktop, really. An old one. About 12 years old. Maybe more. With 8GB RAM and a 1TB spindle drive. It's sitting under my desk. It's pretty big and, honestly, my phone probably has more power. My phone isn't running linux, though (but now I wonder if it will. Hmm.)
Grafana works by connecting to datasources and building queries to populate dashboards. In my case, the database is the mysql server; in particular, it is the coins database on the mysql server.
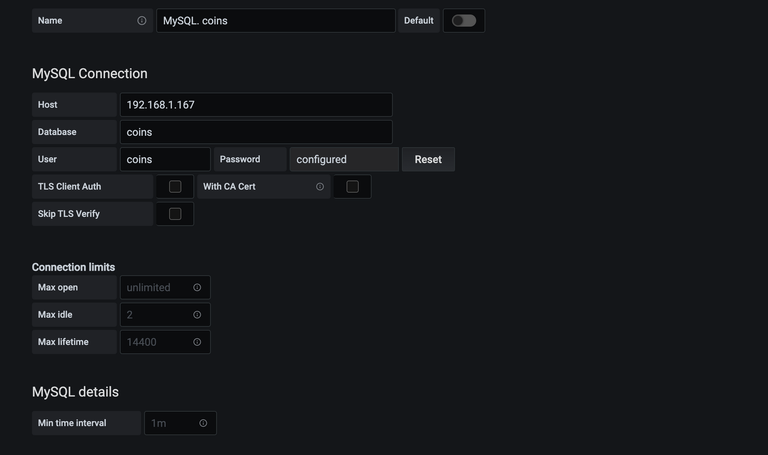
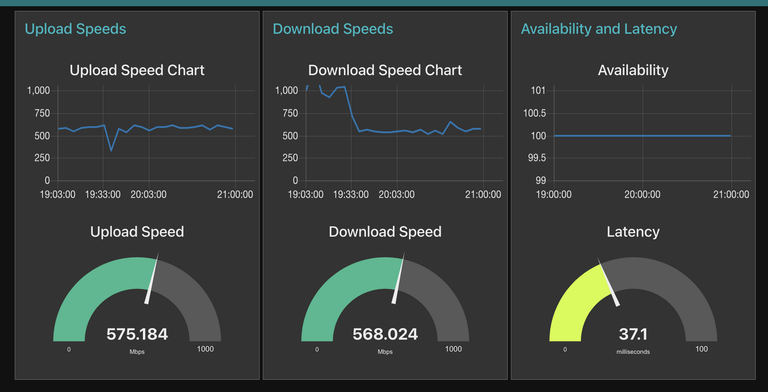
The dashboard itself is named, simply, Coin Values. I don't need to be imaginative for this, otherwise I would have named it The Master Dashboard of All Thee Coin Values Populated In Thou Most Wonderful MariaDB RDBMA and Presented Within.
The dashboard itself looks like this:

There are a few really interesting aspects of this dashboard, even though there are only two items on it:
First, it has a pulldown to interactively choose the coin:
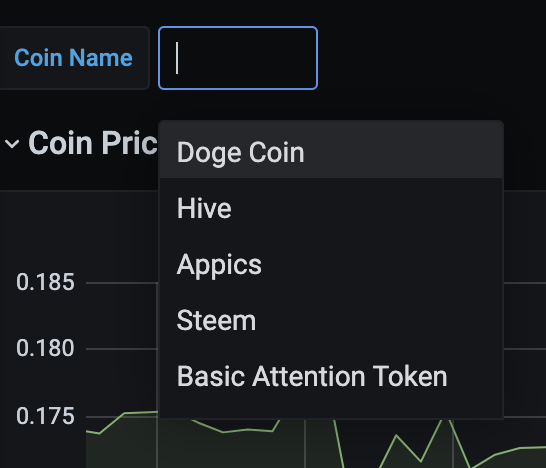
This is done by using a "variable" that is populated with an SQL query, dedicated on this dashboard. The variable is, simply, SELECT coin_name FROM coin_names and is named "CoinName".
The next interesting point is the auto-timeframe feature in the top right corner. Without even needing to do anything Grafana automatically provides a method of choosing the timespan of the dashboard:
It can do this by virtue of the fact that it knows this dashboard is a time series dashboard, or one that has an x-axis of a timeframe.
Building the charts themselves requires some underlying knowledge of the datasource and how it is put together. In this case it is just another SQL query:
SELECT
t1.timestamp AS "time",
t1.value AS "Price USD"
FROM coin_values t1,coin_names t2
WHERE t1.coin_id = t2.coin_id
AND t2.coin_id = (SELECT coin_id FROM coin_names WHERE coin_name = '$CoinName')
ORDER BY t1.timestamp
Remember I had mentioned that the dashboard had a variabled named "CoinName?" You'll see it passed in the SQL query to pull the data as '$CoinName'.
Summary
Node Red and Grafana work really, really well together. This is a simple example of providing some dashboard for time-series data. Depending on the use-case, however, the solution can be as simple or complex as required. Multiple Grafana variables can be used, as well as multiple chart types on the dashboard. Out of the box there are about a dozen different visualisations available, and there are even more available via plugins.
(c) All images and photographs, unless otherwise specified, are created and owned by me.
(c) Victor Wiebe
About Me
Amateur photographer. Wannabe author. Game designer. Nerd.
General all around problem-solver and creative type.
My Favourite Tags
| #spaceforce3 | #altphoto | #crappycameraphotos |
| #digitalpinhole | #pinhole | #firehydrant |

Congratulations @wwwiebe! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
Your next target is to reach 7500 replies.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz: