IPFS in Python
One of the best things to come out of the whole "Web3" umbrella of projects is the IPFS, or Interplanetary File System.

In their own words, IPFS is ...
A peer-to-peer hypermedia protocol designed to preserve and grow humanity's knowledge by making the web upgradeable, resilient, and more open.
What is IPFS really?
I tend to think of IPFS as if Dropbox and BitTorrent had a baby. Like Dropbox, it is a file store and retrieval system, and like BitTorrent, it is "peer to peer" (though the files are not broken into pieces for distribution).
Unlike Dropbox, by default at least, there is no security or version control, so don't store private stuff in clear text!
Rather than using a regular file system, your file is filed away when it is stored by hashing the contents, so two identical files won't take up double the necessary space.
When you request the file based on its unique hash key, the IPFS system will get your file from anyone who has it, and hopefully someone close by with fast internet. It's almost like a CDN in that regard - it can speed up retrieval of files if someone nearby has the file versus a faraway server.
Woah - What about illegal stuff?
In theory, unless you run a gateway, the only files you will collect locally will be stuff that you requested, so that is on you. If you request sketchy stuff, then just like your web browser cache, you will now have a copy of that sketchy stuff stanking up your IPFS node.
That said, again like a browser cache, unless you specifically request for it to stick around (a process called "Pinning") then it will be garbage collected and vanish eventually.
Pinning?
All IPFS nodes treat the data that they are storing just like any other cache, meaning that if you are not using it right now then there is no guarantee the data will continue to be stored into the future. Obviously, this is a good thing in terms of housekeeping, not so great if you come to rely on that file sticking around.
Pinning your file, however, tells your IPFS node that you want the data to be more permanent, therefore make sure you pin any content that you need to be retained over the longer term.
An easy way to do this is to use a pinning service. A pinning service will pin your data for you, for a reasonable cost. This means, of course, you don't have to run and maintain your own dedicated IPFS node, using up your bandwidth and potentially opening up your network to vulnerabilities.
The one I use is Pinata because it has a nice API and it provides new users 1GB of free storage (plenty enough to store your ugly NFT profile pictures) and a very reasonable $0.15 per GB/month.
Running IPFS
If you check out the IPFS website, there are a bunch of downloads, command line installs, and even a browser extension.
For most people who are going to develop large-scale applications, the Go-based CLI is probably the default install.
Simply use your package manager (APT, Homebrew, etc) as usual:
brew install ipfs
If you didn't already install from a desktop app, you will need to run ipfs init to set up your repo.
Then you can run IPFS as a service:
brew services start ipfs
or just as and when needed:
/opt/homebrew/opt/ipfs/bin/ipfs daemon
In another terminal window, enter ipfs id to see if everything is set up ok.
If you already have some files stashed away, you can list them via ipfs pin ls and read a file with ipfs cat followed by the CID of the file you wish to read, eg.
ipfs cat QmQGiYLVAdSHJQKYFRTJZMG4BXBHqKperaZtyKGmCRLmsF
Either way, desktop or CLI, you can still access a nice management user interface as the Daemon provides a web UI on your localhost http://127.0.0.1:5001/webui, it adds another layer of familiarity by way of the Mutable File System (MFS).
MFS is a tool built into the web console that helps you navigate IPFS files in the same way you would a name-based file system.
Pinata API
There are a bunch of services out there that interact with IPFS directly using the HTTP interface we looked at earlier, or via CLI shell commands, but this requires you to be running an IPFS node in your browser or as a service on your computer/server.
Conveniently, Pinata allows you to do things over the regular web using an authenticated REST API.
Go to Pinata.cloud to sign up and then get your API keys.
While Pinata has a lovely user interface and a cute mascot, we want to work with Pinata via code.
For example, to upload a file you could use this endpoint:
https://api.pinata.cloud/pinning/pinFileToIPFS
To save ourselves from having to do the authentication and file stuff, though, let's use a Python library called py-ipfs.
Upload a file
Now we know just enough to make us dangerous, let's upload a Markdown-formatted text file that we will use as the content for our "About" page on our Hive custom front end! (see Part 1 Part 2 Part 3)
Using the text editor of your choice, create a new file, for example:
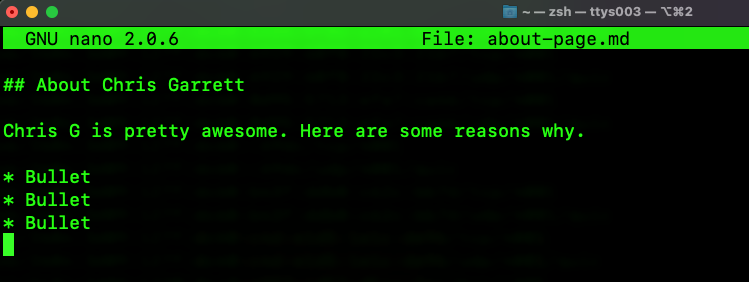
If you are running an IPFS node, then on the command line you can run ipfs add about-page.md and it will return the CID hash key of the newly created file.
Remember this file will only be temporary unless you then pin it using the hash that was returned prevously:
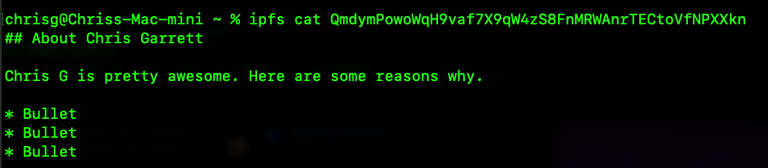
ipfs pin add QmdymPowoWqH9vaf7X9qW4zS8FnMRWAnrTECtoVfNPXXkn
If you now list the pinned files, it will be added to that list ipfs pin ls and you should be able to take a look at it with ipfs cat.
In Python, we can use the Pinata API instead and make their servers do all the heavy lifting!:
import os
import requests
from pinatapy import PinataPy
from dotenv import load_dotenv
load_dotenv() # take environment variables from .env.
# Connect to the IPFS cloud service
pinata_api_key=str(os.environ.get('PinataAPIKey'))
pinata_secret_api_key=str(os.environ.get('PinataAPISecret'))
pinata = PinataPy(pinata_api_key,pinata_secret_api_key)
# Upload the file
result = pinata.pin_file_to_ipfs("markdown.md")
# Should return the CID (unique identifier) of the file
print(result)
# Anything waiting to be done?
print(pinata.pin_jobs())
# List of items we have pinned so far
print(pinata.pin_list())
# Total data in use
print(pinata.user_pinned_data_total())
# Get our pinned item
#gateway="https://gateway.pinata.cloud/ipfs/"
gateway="https://ipfs.io/ipfs/"
print(requests.get(url=gateway+result['IpfsHash']).text)
print(gateway+result['IpfsHash'])
What Now?
This whole deal came up because on my custom Hive website, I want to have static content (like about page, fluff above the contact form, etc), now we can store the CID hash for each piece of raw content and pull that into the page when needed.
Posted with STEMGeeks