Using hiveSQL to find content
I was asked recently about using @hiveSQL as a tool to find 'good posts' to curate, and so at the risk of facing the wrath of @arcange (who may appear in the comments to tell me my query is killing the DataBase), here is a sample query with the code explanations.

middle right, lol
First you will need some login details for hiveSQL. Send 0.01 HBD to @hiveSQL and wait for an encrypted memo. I use peakD and Hive Keychain and so there will be a padlock next to the memo to decrypt it.

Reaz wants dataaa, hiveSQL obliges

Click the padlock to find out what's inside!
Next you will need a tool to connect to the DataBase. I use Linqpad which is free for what we require: https://www.linqpad.net/Download.aspx
Once it is downloaded and installed, you can use the details sent to you via the encrypted memo to connect.
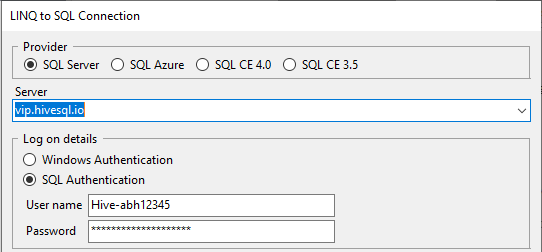
Check 'Remember this connection' at the bottom of this window to save some time
Now you are connected it's time to pull some data. But first, a quick run through the buttons you'll need. From left to right:

Run your query, Stop your query, Rich Text results, and Tabular Results. Also, make sure your Language is set to SQL.
And a note before we start - it is not a good idea to select everything from a table. If your query is running for more than a minute or two, it might be an idea to stop it and have a rethink. It is also not good to use 'LIKE' statements to scan lots of text. I have done that here and but only on a small set of data - there is likely a better way!
Let's start with finding out content created in last 1 hour by author having reputation between 30 to 60 and post having minimum 500 words and reward less than 1$?
This is a fairly basic template, and so I've added some more filters in. The full query is below but I want to break it up to explain various parts.
SELECT
author, A.reputation_ui,'https://hive.blog/'+ url,
left(body,500),
pending_payout_value,
C.created,
body_length as CharacterCount
This is what will hopefully be returned by your query. The author, their reputation, the URL of the post (with your choice of condenser appended to the front, the first 500 characters of text (for an idea of the content), when it was created, and the number of characters in the content. A word count is not available and so dividing that total by 4 or 5 should give a rough idea.
FROM
Comments C
INNER JOIN Accounts A on C.author=A.name
WHERE
The Comments table is where 'posts' and comments/replies are kept. They are treated the same by the blockchain and SQL database, but are distinguishable in the DB using a couple of methods (one is discussed further below). For the author reputation, a join is made to the Accounts table. This is not so important for today but for those who care, the 'C' and the 'A' are aliases given to these tables when referencing them and the columns they hold.
'WHERE'.... stuff ='s other stuff.
(
NOT JSON_QUERY(C.json_metadata,'$.tags') LIKE('%"cn"%')
AND NOT JSON_QUERY(C.json_metadata,'$.tags') LIKE('%"ru"%')
AND NOT JSON_QUERY(C.json_metadata,'$.tags') LIKE('%"kr"%')
)
This is used to filter out tags/topics. I don't know these languages and so wish to exclude them from the results. $.tags is a section of C.json_metadata and so wildcard searching, although painful, is less of an issue. There is likely a better way to do this, and I hope someone can chip in.
AND NOT category IN ('porn','tits','arse','fanny')
The category is the first tag and fortunately has its own column. You can use this to exclude tribes ('hive-XXXXX') or other topics you'd rather not see in the results.
AND depth = 0
This ensures that only top level comments (posts to you and I) are returned and it's use will save time and DataBase pain.
AND NOT author IN ('abh12345','add_spammer_here')
You know those authors who you are sick of seeing each day? You can exclude them here.
AND NOT active_votes LIKE('%"spaminator"%')
Another part of the query to make arcange cry, a wildcard search through the voters so far. In this case, if 'spaminator' has given the thumbs down to the content, it wont appear in the results.
AND datediff(minute, C.created,GEUTCTUTCDATE()) < 60*4
This compares the creation date of the post to this moment in time, converts that into seconds and compares against 60*4 - 4 hours. I ran the query with the suggested 1 hour window and 0 results were returned, damn!
AND A.reputation_ui BETWEEN 30 AND 60
Joining to the Accounts table and using 'A' as the alias, we can check the author reputation. In this case, the reputation will need to be between..... 30 and 60 to appear in the results.
AND pending_payout_value > 0.0100
AND pending_payout_value < 3.0000
The could also be written as a 'BETWEEN' statement and it is to check the current pending payout of the post.
AND body_length > 4000
The post must be at least 4000 characters in length, which if we use 4.79 characters as the average word length, is about 835 words. Fairly chunky for a post these days.
ORDER BY created desc
And finally, the way to order the results. I have used the date with the newest post first.
And here is the query in full:
SELECT
author, A.reputation_ui,'https://hive.blog/'+ url,
left(body,500),
pending_payout_value,
C.created,
body_length as CharacterCount
FROM
Comments C
INNER JOIN Accounts A on C.author=A.name
WHERE
(
NOT JSON_QUERY(C.json_metadata,'$.tags') LIKE('%"cn"%')
AND NOT JSON_QUERY(C.json_metadata,'$.tags') LIKE('%"ru"%')
AND NOT JSON_QUERY(C.json_metadata,'$.tags') LIKE('%"kr"%')
)
AND NOT category IN ('hive','porn')
AND depth = 0
AND NOT author IN ('abh12345','add_spammer_here')
AND NOT active_votes LIKE('%"spaminator"%')
AND datediff(minute, C.created, GETUTCUTCDATE()) < 60*4
AND A.reputation_ui BETWEEN 30 AND 60
AND pending_payout_value > 0.0100
AND pending_payout_value < 3.0000
AND body_length > 4000
ORDER BY created desc
The query above has taken less than a second to return a set of results which has been between 8 and 16 items. To me, that doesn't sound like a lot of posts in the past 4 hours, but obviously it is due to the criteria chosen and this can of course be changed.
And change you will need to, unless you speak Spanish or Polish. Although I did find this one:
https://peakd.com/@gubbatv/posts
And I'm not convinced it is her so I sent a short message and will comment on the post if I find out more.
Edit: Confirmed to be the owner of https://gubbatv.com/
Anyway, I hope this helps @sanjeevm, and anyone else who is interested. If you plan to have a go with the above, check the post again later to see if arcange has commented with some nicer script to replace the wildcard 'LIKE' searches.
Cheers,
Ash
Posted with STEMGeeks
I really ought to play with this. I have done plenty of SQL in the past, so I should be able to get into it.
Nice, then it's just a matter of getting used to the views and what data is where :)
I've logged into the database, but don't see the Hive stuff, just those that define the standard system. I am more used to Oracle than SQL Server, but the principles should be the same.
I'm using a thing called DBeaver on Linux.
Update: Aha! Needed to specify the schema
Glad you found it cause I wouldn't be able to help much i think!
I've not used this tool before. For my Brit List I used Python and beem. SQL may be better for some other things. It's certainly quick. Need to think about what queries I can use. Could investigate some abusers. There's one I know of who is creating lots of accounts. Could check if any have rewards.
I am tempted myself. I used to write loads of queries on my old job and still occasionally do the odd one to keep my hand in.
Simpler times!!
That dB is gonna take a pounding if everyone has a go!! :0)
Yeah it will which is why I tried to make clear the faults and gave something nice and speedy!
You did. It's a really good example to kick off from!!
Cheers :)
And now you can find out cool stuff like how many times downvoted KC :D :O
The downvote counts!! Actually, as soon as I get some time free at work I'm gonna go for it!
So am I responsible for the sin 😁
Hehe, it looks like it!! Heads will roll 😃😃
First @geekgirl is making posts about using @hivesql, now you?
I really have to get to it!
Happy to see what you can come up with in the mean time.
Thought I'd follow the trend, I've been using the thing for 3 years :)
That sounds very complicated. Haha. It would be better if Hive just worked the same way Leo does as far as curation goes.
It's not so bad, if I can do it :)
Great! I used to use that @curie tool but it only works on STEEM, I could use a replacement.
EDIT: Got it working.. I will have a mess around with your code and do some custom stuff next!
Well this one is a fair base template I think - message me on discord if you have an queries.
Its great, got it working.. and its fast.
Nice!
Try and keep the criteria tight and with few free text 'wildcard' searches - arcange will kick my ass otherwise!
Haha, Only ran it twice.., @steevc might be doing more than me, he's also got it all working.
I'm exploring some of the tables. Lots of potential uses. I find enough to vote on anyway.
Congrats, you were upvoted from this account because you were in Top 25 engagers yesterday on STEMGeeks .
You made a total of 11 comments and talked to 8 different authors .
For more details about this project please read here - link to announcement post
You can also delegate and get weekly payouts.
I have a replacement almost ready. Will deploy the App soon.
I could get into this.., haven't done any coding for a while, but I'm a geek at heart!
Is @curie dead on hive ?
No mate, very much alive but more subdued than before. The witness account is hanging around the top 30 and I curate daily for them (if I can find anything worthy!).
Good to hear, it has witness vote from me. However, yesterday, when I went to the page, I saw it was referring to Steem. At least let's update that. Also the certificate is not valid, the browser pops up a warning.
I will ask the gods for you, it doesn't look good.. I have to admit. I haven't been on the website in a couple of years.
Nice! I was working on the exact same thing yesterday. I will deploy searching posts as an App today or tomorrow. It’s almost done. Just having issues displaying body content properly.
Sounds good :) I think people are looking for something simple to use as a search.
I was all excited for a minute there and then you got to the example code. 😂
It's all there, line by line!
Ah. Yes. But I was thinking I'd be able to find out other stuff. 😁
Discord me with a list 🙃
Congratulations @abh12345! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
Your next payout target is 68000 HP.
The unit is Hive Power equivalent because your rewards can be split into HP and HBD
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
I was following to the top 3rd but I think I concede defeat in SQL! The queries we (you) made for HMRC will be my limit, this is next level wizardry!
Looking at different views/tables here with more filter criteria but if you know what the columns mean it's not so complicated. Glad you got started with a practical example though!
Yes, I think it's just a case of knowing the names of columns that are used to select the data - but you can find that just by looking in to the views in that SQL software you shared. Pretty happy we went through what we needed to - now we just need HIVE designed fountain pens and we'd be sorted 😃
Don't look at me as the seller, I cannot be arsed accounting for another income stream!
Hahaha! Stick to biro!
You're teaching sorcery ... 🚶🚶🚶
🤣😁
Finally......👌I am going to explore more. I use Squirrel SQL Client which is also free - do you think a detailed post on how to use that would help ?
The tool isn't so important, I only use the buttons I mentioned and haven't used Squirrel. I hope you find the example useful!
Well I got as far as down loading the program, and then two updates for the program to work, then was actually able to connect to the database. Now all I need to do is figure out how to get stuff out, that will be another day. I need to work on my spreadsheet a little bit and figure out how to use the data base to populate it with just the stuff I want.
Such as from my account only rewards for the last seven days, how to get it for the entire month and how much since just the beginning of Hive.
Each month has a different number of days, so I really don't want just the 30 day results but the whole month results. So a sample query might help me if you can work one up for me, I have a little bit of HBD saved, (3.793) I haven't converted it lately, and some non powered up Hive, (40). Give me a price, I know I don't have much but I can scrimp and save.
There is a lot of information available from him.
First, no need to send me anything :)
This is your author rewards (liquid only) for Steem up to the 20th March 15:30 and for Hive from that point onwards.
They are grouped into days. If you pivot table this in Excel then you should be able to choose between weeks/quarters/years.
If you want a more accurate rewards total, it might be an idea to use sum(hive_payout)2 (2 on each) to account for vested rewards.
Curation, as it's only given in Vests, is tougher to find a value for as Vests per STEEM/HIVE is always rising.
You can find the current Vests per Hive on hivetasks.com under the Market tab.
It was around 480 in at the end of 2017, so I've taken the middle ground:
Something to get you started I hope , enjoy!
Thank you. I first tried the newest version of LINQPad 6, then had to go back to LINQPad 5 because I got some error, but the Version 5 worked right off the bat.
Even took a little bit to remember to pick SQL on the language, so thank you that will be a big help. Yeah getting a good conversion from vest is not to easy a thing I guess, like converting the HBD to Hive, ever changing prices.
That will help me a lot to begin my exploration, I did not want to worry about bogging the system down with comparing lots of accounts, just interested in my own. Now time to learn more about making the queries.
heck yeah this is super neat, Always good to help people find stuff.
Cheers!
The way I do it is expand the json out and use it as a join and cross apply, kind of a pain in the ass but works good. Every query that uses this is a brain teaser.
Yeah that sounds nasty, but probably better/quicker. Got an example? :D
I like it, cheers!
Congrats, you were upvoted from this account because you were in Top 25 engagers yesterday on STEMGeeks .
You made a total of 3 comments and talked to 3 different authors .
Your rank is 5 .
For more details about this project please read here - link to announcement post
You can also delegate and get weekly payouts.
This is a
really greatpost on how to use HiveSQL, but...Fear my wrath! You made mistakes again! 👿
This is a useless waste of resources to recomputes body length for each comment, each time you send your query. Have you ever looked at the columns of the table: there is a
body_lengthcolumn with such precomputed value!Another noobish error: all dates and times stored in the blockchain (and in HiveSQL) are UTC based. Therefore, you need to use
GETUTCDATE()when comparing dates.Contrary to what you think, I have nothing against this part of your WHERE clause.
Of course, this remark is only valid because your WHERE clause contains enough other conditions that will use the indexes before the additional filtering with the LIKE is performed.
Don't tell me you did it twice 🤦♀
Mistakes, or opportunities for you to improve my work :)
Thank you for running HiveSQL, I shall correct my wrong doings and bow to YodaSQL on my departure.
Congrats, you were upvoted from this account because you were in Top 25 engagers yesterday on STEMGeeks .
You made a total of 4 comments and talked to 4 different authors .
Your rank is 1 .
For more details about this project please read here - link to announcement post
You can also delegate and get weekly payouts.
Good boy you are! 👍
🤣
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider supporting our funding proposal, approving our witness (@stem.witness) or delegating to the @stemsocial account (for some ROI).
Please consider using the STEMsocial app app and including @stemsocial as a beneficiary to get a stronger support.
Thanks guys!
Amazing.
I always use python to connect to HiveSQL .
Just curious , if you want to retrieve all the comments for past 30 days, can I know how much time it takes?
Congrats, you were upvoted from this account because you were in Top 25 engagers yesterday on STEMGeeks .
You made a total of 3 comments and talked to 2 different authors .
Your rank is 3 .
For more details about this project please read here - link to announcement post
You can also delegate and get weekly payouts.
Wicked work
Thanks!
Great post! Thank you for the illustration!Wondering if it is possible to check power down power up metrics using hive SQL..
Yes I think that is there.
Power ups
select * from txtransfers where [from] = 'drniche'
and type = 'transfer_to_vesting'
order by timestamp asc
Power downs are in Vests, and so the HIVE amount is only approximate (as the number VESTS per HIVE is constantly increasing).
select , vesting_shares525/10000000 as approx_HIVE from TxWithdraws
where account = 'abh12345' and vesting_shares <> '0.000000'
order by timestamp asc
From the Market Info tab on https://hivetasks.com/@drniche
This is wonderful!! Thank you so much! I will try it out in the database tonight.
Awesome post! Thank you for sharing this information. It was easy to follow and I was able to query after about 15 minutes. My only comment was when I transfered 0.01 HBD to @hiveSQL, I received an error, so I needed to change the name to @hivesql.
I didn't realized the hiveSQL database is free. That's so cool. Do you know who is funding it to be free? Also, do know if I can query Splinterlands DEC transfers with this database? I am able to query this information through the Splinterlands API, however the transfers data is limited to a 30 day window. I do not know of another way to obtain transfers that are older than 30 days. Do you?
Ah cool, thanks for checking it out and for that correction.
It didn't used to be free, I paid 40 SBD/HBD a month for years, but:
https://peakd.com/me/proposals - see about 7 down.
This might be in TxCustoms, but I think it is on the sidechain. I don't deal with that one but perhaps @dalz or @gerber could be so kind to post a guide or a comment here :)
I appreciate the guidance and for reaching out for more help.
I use this query for DEC transfers to null ... you need to parse the json data as well
Ah nice, so you could do something like this then...
That will do it :)
Testing it soon!
Thanks abh12345, you and @dalz really came through for me today. I like how you parsed some of the json string.
FYI - when we use [tid] = ('ssc-mainnet-hive'), we get transfers on the Hive engine.
When we used [tid] = ('sm_token_transfer'), we get in-game transfers.
Good to know :)
I've not looked at this table much, mainly out of fear of its size and the json parsing, but I think I'll pay a bit more attention to it in future. Thanks for opening up the conversation, and cheers dalz!
Thanks so much for your prompt reply. Your query sample was very helpful. I was able to update the where clause to obtain exactly what I needed. I had no clue all this data was available all this time. This is very cool.
(This is for @arcange to continue from comment left at https://ecency.com/hive-168869/@arcange/re-1657869089260.)
@hivesql sent me the encrypted memo (along with a refund of 0.001 HBD).
Hive Keychain is required to view the encrypted memo, so for memo purposes I switch to Peak D before I launch Keychain.
Keychain doesn't know about my Memo Key, so I need to import it; however, when I go to import the Memo Key I get this error message from Keychain:
I'm using a mobile hotspot, so I don't understand why I need to use WIFi of any kind. So at the moment I'm at a dead end. I don't know how to proceed from here.
I don't think it's a good idea to comment on an unrelated post.
Your problem is related to Keychain, not HiveSQL.
If you read the error message carefully, you will see that it says "This is not a private WIF (and not WIFI) which means that the encoded private key is not valid.
Support for Keychain is provided on their Discord
Support for HiveSQL is also provided on Discord