[ESP-ENG] Titulos y enlaces en statology || Titles and links in statology
 Imagen diseñada con canva || Image designed with canva
Imagen diseñada con canva || Image designed with canva
Saludos mis hivers. En esta oportunidad les traigo otro script elaborado en Python con el objetivo de obtener títulos y enlaces del sitio web statology.
Para los que quieran incursionar en el mundo de la ciencia de datos, este sitio web es ideal para aquellos que quieran aprender a usar las herramientas básicas o estándar para realizar labores de carácter científico usando los lenguajes de programación como Python y R, pues son los de mayor empleabilidad en esta disciplina y también aprenderemos sobre los fundamentos que sustentan la interpretación y análisis de resultados estadísticos.
También dispone de tutoriales para aprender a usar Excel y Google Sheets sumando a ello el uso de librerías muy populares como Numpy, Pandas, Matplolib y seaborn de Python y Tidyverse de R .
Creo que es un sitio web que vale la pena compartir con ustedes por acá y de hacer un script sencillo en el que podemos usar para encontrar tutoriales o guías que nos pueda ayudar en nuestras labores.
Bueno mis queridos hivers, esto es todo lo que comparte hoy con ustedes. Gracias por visitar mi blog. Hasta la próxima entrega.
Este script fue ejecutado con Python 3.9.13 en el sistema operativo Lubuntu 18.0.4.
Greetings my hivers. In this opportunity I bring you another script elaborated in Python with the objective of obtaining titles and links from the statology website.
For those who want to venture into the world of data science, this website is ideal for those who want to learn to use the basic or standard tools to perform scientific work using programming languages such as Python and R, as they are the most employable in this discipline and also learn about the fundamentals that support the interpretation and analysis of statistical results.
It also has tutorials to learn how to use Excel and Google Sheets adding to it the use of very popular libraries such as Numpy, Pandas, Matplolib and seaborn from Python and Tidyverse from R .
I think it is a website that is worth sharing with you here and to make a simple script that we can use to find tutorials or guides that can help us in our work.
Well my dear hivers, this is all I share with you today. Thanks for visiting my blog. See you next time.
This script was run with Python 3.9.13 on the Lubuntu 18.0.4 operating system.
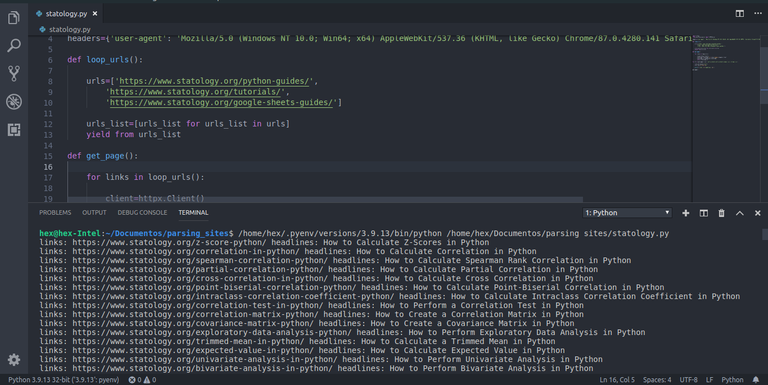
import httpx
from selectolax.parser import HTMLParserheaders={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75'}
def loop_urls():
urls=['https://www.statology.org/python-guides/', 'https://www.statology.org/tutorials/', 'https://www.statology.org/google-sheets-guides/'] urls_list=[urls_list for urls_list in urls] yield from urls_listdef get_page():
for links in loop_urls(): client=httpx.Client() statology=client.get(url=links,headers=headers).text statology_str=HTMLParser(statology) return statology_strfor hl in get_page().css('.entry-content.entry-content-single > p > strong > a'):
l=hl.attributes['href'] h=hl.text(strip=True) print(f'links: {l} headlines: {h}')get_page()
Congratulations @pynomiems! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 2000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!