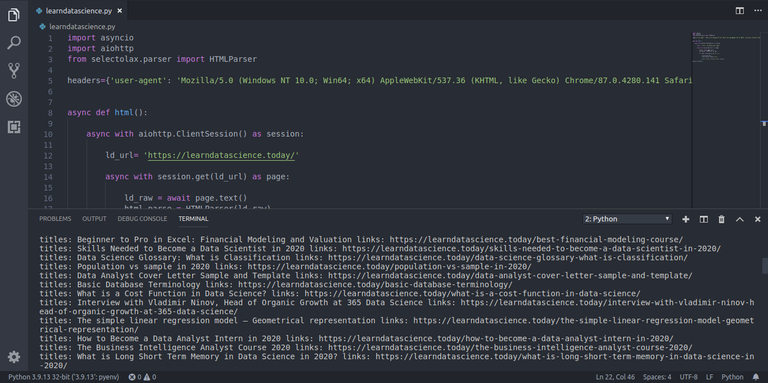
[ESP-ENG] Títulos y enlaces en learndatascience || Titles and links in learndatascience
 Imagen diseñada con canva || Image designed with canva
Imagen diseñada con canva || Image designed with canva
Saludo hivers. Otra vez con mis pequeñas invenciones en Python. Esta vez se trata de un script que usaremos para obtener los enlaces y títulos del sitio web learndatascience.
Learndatascience, no es más que un blog que se enfoca en ofrecernos información sobre ciencia de datos y blockchain. Es decir, encontraremos guías, tutoriales y noticias sobre esta área del saber que está en continuo crecimiento y que al pasar de los años se ha convertido en uno de los oficios más demandas por empresas e instituciones del sector TI.
No solo encontraremos guías, también ofrece cursos certificados que, al parecer-no he tomado ninguno de estos cursos-, son muy buenos en cuanto al programa de contenidos anexados en los módulos de los cursos. Por ejemplo, https://learndatascience.today/web-scraping-and-api-fundamentals-in-python-2020/. Este me parece interesante, es un curso para aprender webscripting con Python, usando la librería request-html ideal para iniciados en este complejo e interesante mundo del webscripting.
Bueno, creo que es suficiente. Les dejo el script con sus respectivos resultados y el acceso a este sitio web para que generen sus propias conclusiones.
Hasta la próxima entrega. Gracias por su visita.
Este script fue ejecutado con Python 3.9.13 en el sistema operativo Lubuntu 18.0.4.
Greetings hivers. Again with my little inventions in Python. This time it is a script that we will use to get the links and titles of the learndatascience. website.
Learndatascience, is nothing more than a blog that focuses on offering us information about data science and blockchain. That is, we will find guides, tutorials and news about this area of knowledge that is continuously growing and that over the years has become one of the most demanded professions by companies and institutions in the IT sector.
Not only will we find guides, it also offers certified courses that, apparently -I have not taken any of these courses-, are very good in terms of the content program attached to the course modules. For example, https://learndatascience.today/web-scraping-and-api-fundamentals-in-python-2020/. I find this one interesting, it is a course to learn webscripting with Python using the request-html library ideal for beginners in this complex and interesting world of webscripting.
Well, I think that's enough. I leave the script with their respective results and access to this website to generate their own conclusions.
Until next time. Thanks for your visit.
This script was executed with Python 3.9.13 on Lubuntu 18.0.4 operating system.
import asyncio
import aiohttp
from selectolax.parser import HTMLParserheaders={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75'}
async def html():
async with aiohttp.ClientSession() as session: ld_url= 'https://learndatascience.today/' async with session.get(ld_url) as page: ld_raw = await page.text() html_parse = HTMLParser(ld_raw) for find in html_parse.css('h2 > a'): titles=find.text() links=find.attributes['href'] print(f'titles: {titles} links: {links}')asyncio.run(html())