[ESP-ENG] Enlaces, títulos e imágenes de Nature || Links, titles and images from Nature

Hola Hivers. He creado un script con el propósito de obtener los enlaces, títulos e imágenes en un sitio especializado en divulgar información científica y ese sitio es Nature. La revista Nature Ha dedicado un amplio trayecto para mantener a la comunidad científica y publico en general sobre los hallazgos más importantes en el ámbito de las ciencias. La primera publicación ocurrió en 1869 y fue fundada por Joseph Norman Lockyer. En la actualidad el Sitio web de Nature recibe nueve millones de visitas por mes logrando así en convertirse en uno de los sitios web más populares del internet en cuanto al acceso y divulgación de contenido científico.
De acuerdo a lo expuesto, Me sentí motivado en hacer un script para el propósito que describí anteriormente. Esta vez logre escribir un script con una sintaxis más compleja y dinámica, tal y como lo mencione en mi publicación anterior.
Espero que este script sea una excelente referencia para adaptarlos a sus proyectos; que puedan resolver algún problema o puedan aclarar dudas.
Pueden dejar sus comentarios y con gusto los atenderé. Abajo adjunto el código con sus respectivos resultados.
Este script fue ejecutado con Python 3.9.2 en el sistema operativo Debian Bullseye.
Hi Hivers. I have created a script for the purpose of obtaining the links, titles and images on a site specialized in disseminating scientific information and that site is Nature. Nature magazine has dedicated a long way to keep the scientific community and the general public abreast of the most important findings in the field of science. The first publication occurred in 1869 and was founded by Joseph Norman Lockyer. Currently, the Nature website receives nine million visits per month, making it one of the most popular websites on the Internet in terms of access and dissemination of scientific content.
According to the above, I felt motivated to make a script for the purpose I described above. This time I managed to write a script with a more complex and dynamic syntax, as I mentioned in my previous post.
I hope that this script will be an excellent reference to adapt it to your projects; that you can solve some problem or clarify doubts.
You can leave your comments and I will be glad to help you. Below I attach the code with their respective results.
This script was executed with Python 3.9.2 on Debian Bullseye operating system.
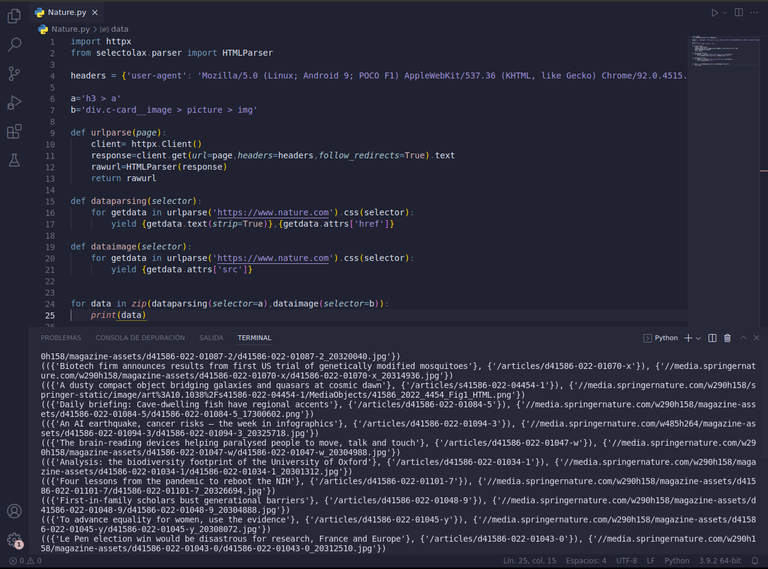
import httpx
from selectolax.parser import HTMLParserheaders = {'user-agent': 'Mozilla/5.0 (Linux; Android 9; POCO F1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.115 Mobile Safari/537.36'}
a='h3 > a'
b='div.c-card__image > picture > img'def urlparse(page):
client= httpx.Client()
response=client.get(url=page,headers=headers,follow_redirects=True).text
rawurl=HTMLParser(response)
return rawurldef dataparsing(selector):
for getdata in urlparse('https://www.nature.com').css(selector):
yield {getdata.text(strip=True)},{getdata.attrs['href']}def dataimage(selector):
for getdata in urlparse('https://www.nature.com').css(selector):
yield {getdata.attrs['src']}for data in zip(dataparsing(selector=a),dataimage(selector=b)):
print(data)
Fuentes || Sources
https://es.wikipedia.org/wiki/Nature
https://www.nature.com/nature-portfolio/about
Congratulations @pynomiems! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 800 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Support the HiveBuzz project. Vote for our proposal!