Podping update: Hive devs especially Python Beem I need your help!
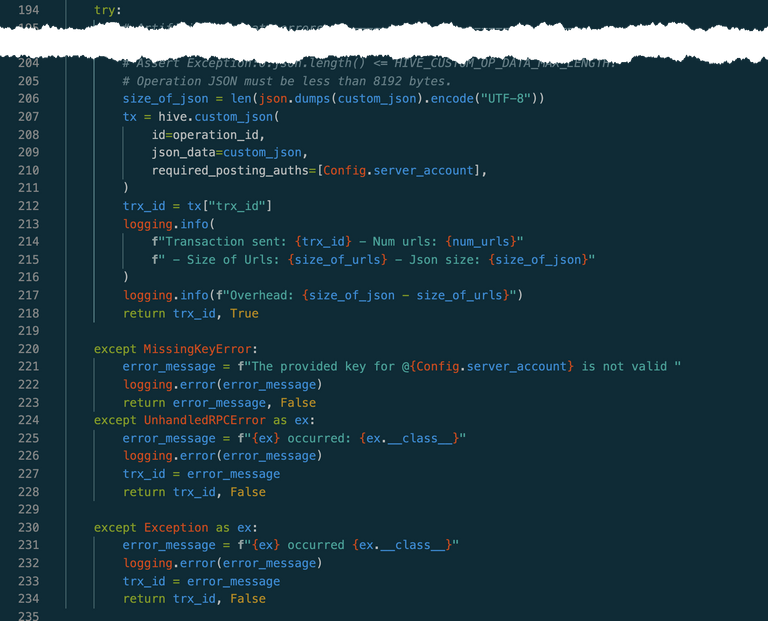
Here's my ask, from the Hive Dev community: this is the functional part of our code that writes to Hive. What kind of error trapping and reporting can we put in place around this? How can we make this bullet proof? The explanation is below the code...
Code on Github in latest Dev version
I'll explain why, I would benefit from some help from those of you with significant experience running Python based Hive apps. I've done pretty well up to now, but we're trying to build something strong and resilient that just runs and I need to know more about what's going on under the hood of Beem and Hive working together.
The story so far, I threw together a very quick proof of concept in a day. After a couple of weeks the code had come together and by 15th of May, in a rather haphazard way, the following code was being run in production as a new service called Podping
Github link to first beta version of Podping running since May 15
That code started running on 3 Linode $5 servers and just run from the command line in a terminal window with a separate Rust based API front end feeding URLs through a ZMQ socket.
That code ran non stop, unattended without error until yesterday when this is the last block it sent:
https://hiveblocks.com/tx/cdb633b5c9bec6e5b097083e9d232308500aa66e
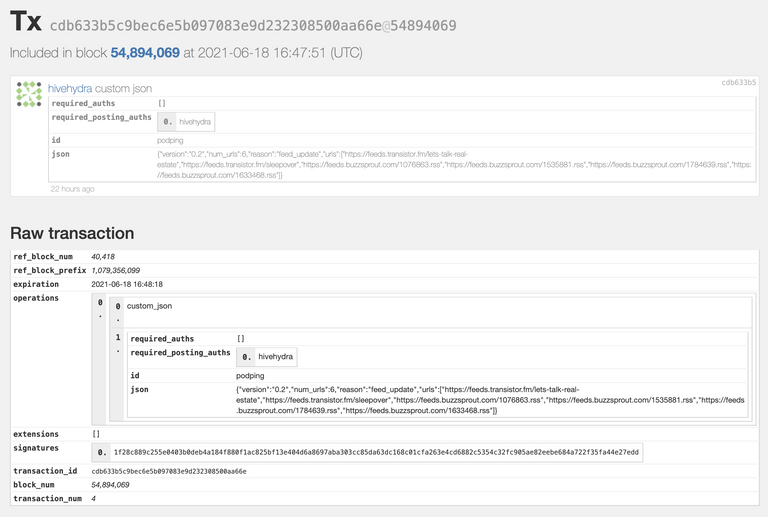
The Beem Error we got is this:
missing required posting authority: Missing Posting Authority hivehydra occurred: <class'beemapi.exceptions.UnhandledRPCError'>
It went through a number of retries but failed each time with the same error. There were no changes to the @hivehydra account which has been sending the pings and I don't know why, after more than 1 month, it failed this way.
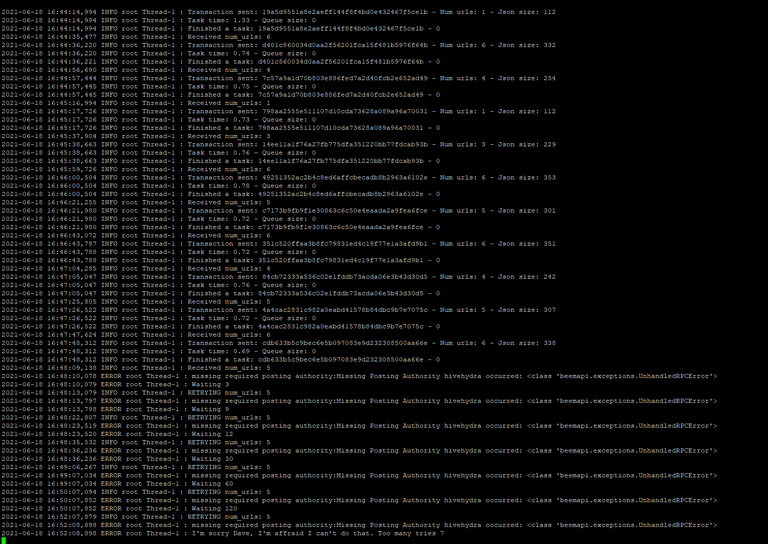
After too long, finally the server was restarted without any config or other changes and it carried on running. We did miss a bunch of pings and the code is deficient in terms of logging URLs it failed to send out, we'll have to fix that.
The new version we're almost ready to deploy is massively different to this one. It's now running with Python's Asyncio functionality, it's running in a Docker and there will be a library in Pypi. There's much better professional structure around the project thanks to @alecksgates but we haven't deployed it yet because it's not done and because, frankly the other version was running non stop without a glitch for a month!
Here's my ask, from the Hive Dev community: this is the functional part of our code that writes to Hive. What kind of error trapping and reporting can we put in place around this? How can we make this bullet proof?
Code on Github in latest Dev version
And finally a little update on the Proposal and funding:
So far most of the HBD received by @podping has been converted directly to Hive and powered up. I'm getting ready to run with new accounts (not @hivehydra) and I'm delegating to those accounts. If I need to compensate for someone's time in reviewing this code, I'm prepared to do that.

- Vote for APSHamilton's Witness KeyChain or HiveSigner
- Vote for APSHamilton's Witness direct with HiveSigner
- Get Brave
- Use my referral link for crypto.com to sign up and we both get $25 USD
- Sign up for BlockFi
- Find my videos on 3speak
- Join the JPBLiberty Class Action law suit
- Verify my ID and Send me a direct message on Keybase
Wow what a fantastic development. Honestly this will help to minimise the errors and error messages that normally occur
I think the developer of Beem is @holger80 and recently the @blocktrades team has been updating the library as well (here: https://gitlab.syncad.com/hive/beem ) so hopefully some of them can help or maybe you can open an issue in the repository to ask for advise.
I am no python dev, nor a blockchain dev, but I did take a look at the Beem library a bit and I would think the class UnhandledRPCError does nothing except just gives you the error Beem got from the RPC node (if I'm understanding how all this works). Why would the RPC node suddenly give an error about a missing posting key authority? Maybe the node was down for a bit or had some temporary issue. If your code was running without any problems for a month, node issues would seem like one likely culprit for the failure happening. A possible mitigation then would be to check for any node-related errors in your code and try another node if the current one gives you an error.
But why did you keep getting this error for a time? A possible explanation would be that the node had an issue for some time, though it could also be something else. Again, not a python or a blockchain dev, just speaking from experience and throwing it out there in case it may be useful.
Thanks. I am looking at being more discerning over node choice.
I don't know anything about coding but I hope you can fix it because I follow your project closely and it looks great!