Extraer datos de endpoints de Hive.blog con Python
Desde hace un mes he estado extrayendo datos de las publicaciones de hive para crear los reportes de curación, esto usando los enlaces de hive.blog, ecency.com y peakd.com. El método usado fue el Web Scraping con la biblioteca BeautifulSoup. Durante todo el mes de abril funcionó perfectamente, y sigue funcionando. Lo interesante de la programación es que por lo general existen muchas formas de solucionar un problema, razón por la cual seguí investigando y estudiando la documentación de Hive para modificar el código y obtener los datos de manera más óptima.
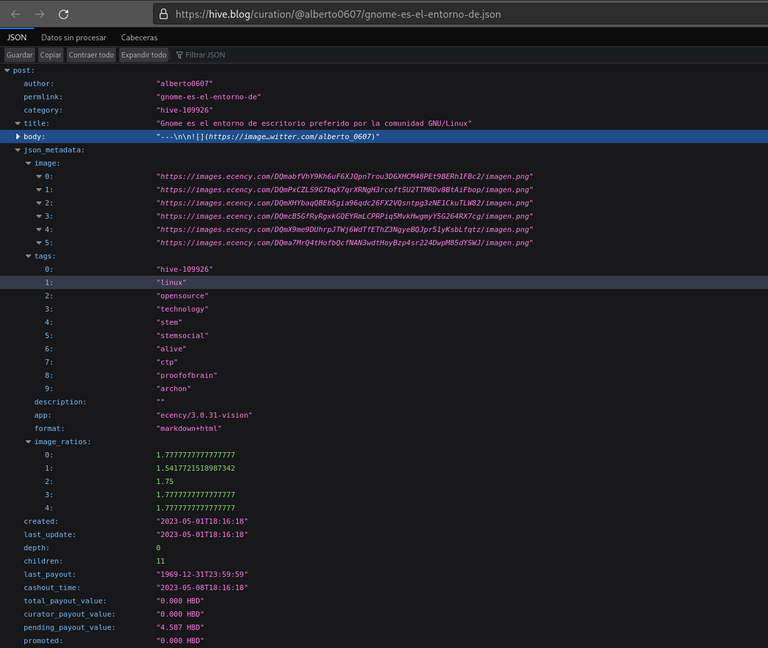
Hive ofrece un servicio gratuito y libre que proporciona información completa de usuarios y publicaciones, estos son los endpoint. La información está en la Documentación para desarrolladores de Hive. Los endpoints son enlaces que contienen los datos del perfil de usuario y publicaciones en formato JSON. Al estar la información en formato JSON facilita la extracción de los datos y la manipulación de los mismos.
En esta oportunidad voy a mostrar un ejemplo muy sencillo, usando el lenguaje de programación Python, de cómo a partir de un enlace de una publicación de hive.blog, ecency.com o peakd.com, obtener: autor, título de la publicación y el enlace de la imagen de portada.
El flujo del script es el siguiente:
Importar las bibliotecas requests y json.
Formatear el enlace de la publicación para que apunte a endpoint. La dirección del endpoint apunta
https://hive.blog/curation/@usuario/permlink.json.
Ejemplo:
https://ecency.com/hive-109926/@alberto0607/gnome-es-el-entorno-de
Formatear a:
https://hive.blog/curation/@alberto0607/gnome-es-el-entorno-de.json
Realizar una solicitud HTTP al endpoint y cargar el json a un variable para analizarlo.
Extraer los datos del objeto e imprimir en pantalla.
Código fuente:
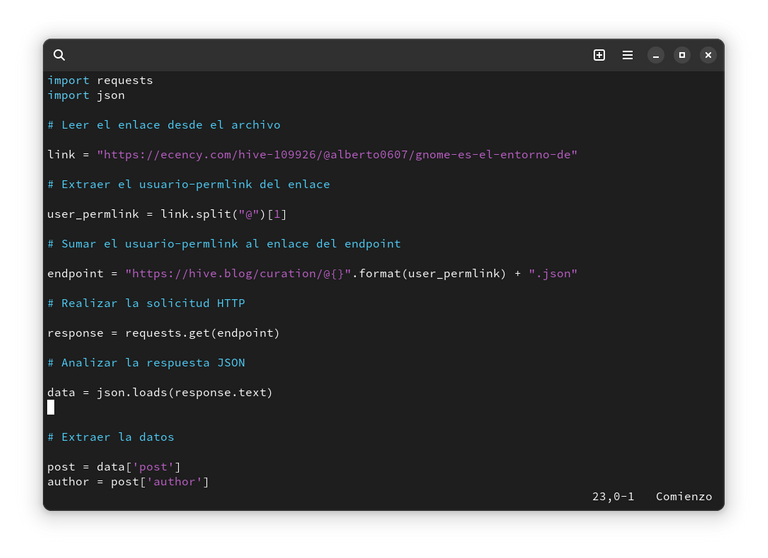
import requests
import json
# Leer el enlace desde el archivo
link = "https://ecency.com/hive-109926/@alberto0607/gnome-es-el-entorno-de"
# Extraer el usuario-permlink del enlace
user_permlink = link.split("@")[1]
# Sumar el usuario-permlink al enlace del endpoint
endpoint = "https://hive.blog/curation/@{}".format(user_permlink) + ".json"
# Realizar la solicitud HTTP
response = requests.get(endpoint)
# Analizar la respuesta JSON
data = json.loads(response.text)
# Extraer la datos
post = data['post']
author = post['author']
title = post['title']
image = post['json_metadata'].get('image', [])[0]
# Salida de los datos
print(f"Link: {link}")
print(f"Author: {author}")
print(f"Title: {title}")
print(f"Image: {image}")
Salida de ejemplo:
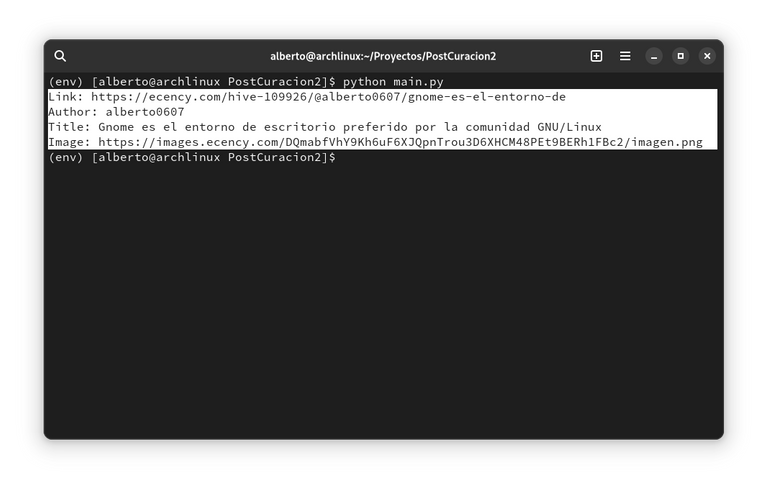
Esta es una forma sencilla de obtener datos y manipularlos utilizando endpoints, ya que son un estándar en la programación y es perfectamente aplicable a cualquier lenguaje.
Poco a poco he estado leyendo y aprendiendo de la API y los servicios de Hive, con el fin de mejorar los procesos del proyecto Visualblock, así como también compartir lo aprendido con la comunidad y a quién le pueda ser útil.
Si desean compartir en los comentarios información adicional, ejemplos, proyectos, sobre la API de Hive, será bienvenido. Gracias por leer, compartir y comentar.
Las imágenes son mías o capturas de pantalla tomadas por mí, a menos que se indiquen fuentes externas.
Discord: alberto0607#6813
Twitter: alberto_0607
Me parece que hiciste un trabajo excelente.
Eso te ahorra bastante tiempo, sé que no tienes mucho y te saturas.
Bien por tí y tu excelente trabajo para tu comunidad. 💜
Tu y Óscar hacen un excelente equipo.
Muchas gracias, la verdad que sí, me da más tiempo para ocuparlo en actividades dentro de hive. Un abrazo.
Saludos. Gracias por compartir tus conocimientos.
A la espera de nuevas entregas
Excelente aporte profe. Falta en la explicación, me salto algunos pasos para ir directo al tema. No se si tenga algún post sobre entornos virtuales en Python. Yo lo uso porque es la mejor forma de manejar las dependencias.
Los entornos virtuales nos facilitan mucho las cosas. Lo coloqué así para llevar la secuencia de lo que hice. También sirve para llamar la curiosidad a los demás lectores. Tu explicación esta muy bien hecha y muy centrada. Gracias nuevamente por compartir tus conocimientos
Yo tengo mis notas, son muchos comandos. Si sumamos a los que uso linux, más los que uso en python, git y algunos de nodejs, la cabeza no me da.
!ALIVE
@alberto0607! You Are Alive so I just staked 0.1 $ALIVE to your account on behalf of @oscarps. (2/10)
The tip has been paid for by the We Are Alive Tribe through the earnings on @alive.chat, feel free to swing by our daily chat any time you want.

Yay! 🤗
Your content has been boosted with Ecency Points, by @alberto0607.
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more