Actualización del Script - Extraer datos de post de Hive usando Web Scraping
La semana pasada presenté un post con un script para extraer datos de publicaciones de Hive. Esto con el fin de automatizar tareas para la creación de post de curación. Este script lo he usado durante toda la semana y la verdad que me hecho ahorrar tiempo significativo.
El script sólo recibía enlaces de https://ecency.com, lo que resultaba una limitante para usuarios que usan el servicio de https://peakd.com, siendo esta última la interfaz más usada por los usuarios de hive.
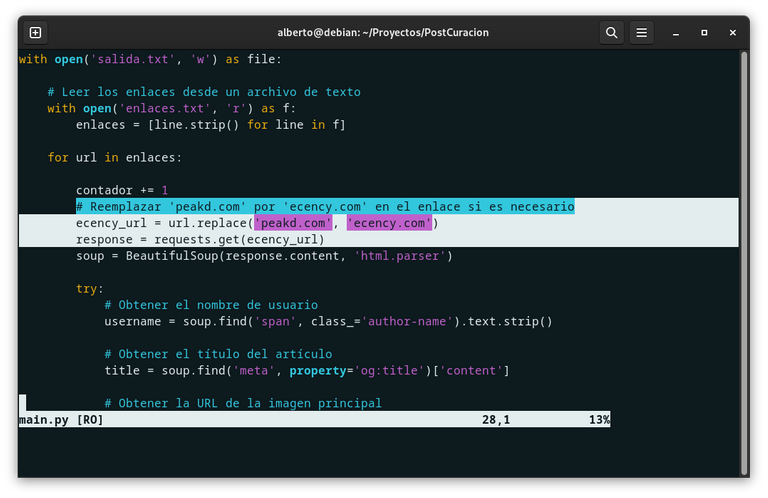
He realizado unos cambios al script con una solución muy sencilla al problema. Usando el método ecency_url = url.replace('peakd.com', 'ecency.com'), lo que hace es remplazar todas las apariciones de 'peakd.com' por 'ecency.com', guardando toda la cadena de texto en una nueva variable ecency_url, para que se ejecute el ciclo for extrayendo todos los datos de los enlaces ecency.com. Además en pantalla se imprime el enlace original suministrado por el usuario.
Con este simple cambio, se le puede dar al script enlaces peakd.com y enlaces ecency.com y seguiría devolviendo una respuesta válida.
Código fuente:
import requests
from bs4 import BeautifulSoup
contador = 0
# Abrir el archivo de texto para escribir la salida
with open('salida.txt', 'w') as file:
# Leer los enlaces desde un archivo de texto
with open('enlaces.txt', 'r') as f:
enlaces = [line.strip() for line in f]
for url in enlaces:
contador += 1
# Reemplazar 'peakd.com' por 'ecency.com' en el enlace si es necesario
ecency_url = url.replace('peakd.com', 'ecency.com')
response = requests.get(ecency_url)
soup = BeautifulSoup(response.content, 'html.parser')
try:
# Obtener el nombre de usuario
username = soup.find('span', class_='author-name').text.strip()
# Obtener el título del artículo
title = soup.find('meta', property='og:title')['content']
# Obtener la URL de la imagen principal
image_url = soup.find('meta', property='og:image')['content']
# Escribir la salida en el archivo de texto
file.write(f"""
#### Post #{contador}
---
{image_url}
---
[{title}]({url})
by @{username}
---
""")
# Imprimir la salida en la consola
print(f"""
#{contador}
Usuario: {username}
Título del Post: {title}
Url de la imagen: {image_url}
---
""")
# Escribir el enlace original en la salida
print(f"Original Link: {url}\n")
except Exception as e:
# Manejar los errores y escribirlos en el archivo de texto
print(f"Error procesando el enlace {ecency_url}: {e}\n")
print("La salida se ha generado exitosamente en el archivo 'salida.txt'")
Salida de ejemplo:
Para más información ir al post.
Espero que le sea de utilidad. Puede clonar el código fuente desde los repositorios de Github para su libre uso. Ver aquí. Allí obtendrá información adicional para instalación del entorno virtual e instalación de bibliotecas. Cualquier comentario o aporte para el código es bienvenido.
Las imágenes son mías o capturas de pantalla tomadas por mí, a menos que se indiquen fuentes externas.
Discord: alberto0607#6813
Twitter: Twitter
!ALIVE
!VSC
!PGM
!LOLZ
@oscarps has sent VSC to @alberto0607
This post was rewarded with 0.1 VSC to support your work.
Join our photography communityVisual Shots
Check here to view or trade VSC Tokens
Be part of our Curation Trail
@oscarps ha enviado VSC a @alberto0607
Éste post fue recompensado con 0.1 VSC para apoyar tu trabajo.
Únete a nuestra comunidad de fotografía Visual Shots
Consulte aquí para ver o intercambiar VSC Tokens
Se parte de nuestro Trail de Curación
@alberto0607! You Are Alive so I just staked 0.1 $ALIVE to your account on behalf of @oscarps. (4/10)
The tip has been paid for by the We Are Alive Tribe through the earnings on @alive.chat, feel free to swing by our daily chat any time you want.

https://twitter.com/750698046489583616/status/1647959727551180804
The rewards earned on this comment will go directly to the people( @alberto0607 ) sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
Yay! 🤗
Your content has been boosted with Ecency Points, by @alberto0607.
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more
Sin duda una buena herramienta de trabajo, para agilizar la tarea diaria dentro la plataforma 😎
Me he ahorrado mucho tiempo y evito errores. Gracias por comentar man
Estas son las herramientas que valen la pena para ser feliz en la web3 jajajaja, saludos bro 😁
No me has escrito a discord
No vale... esa dapp me esta fallando mucho, la borré del móvil porque se cierra, ya la voy a instalar nuevamente, tantos datos colapsan todo jajaja, en la tarde nos comunicamos 😎
¡Enhorabuena!
✅ Has hecho un buen trabajo, por lo cual tu publicación ha sido valorada y ha recibido el apoyo de parte de CHESS BROTHERS ♔ 💪
♟ Te invitamos a usar nuestra etiqueta #chessbrothers y a que aprendas más sobre nosotros.
♟♟ También puedes contactarnos en nuestro servidor de Discord y promocionar allí tus publicaciones.
♟♟♟ Considera unirte a nuestro trail de curación para que trabajemos en equipo y recibas recompensas automáticamente.
♞♟ Echa un vistazo a nuestra cuenta @chessbrotherspro para que te informes sobre el proceso de curación llevado a diario por nuestro equipo.
🏅 Si quieres obtener ganancias con tu delegacion de HP y apoyar a nuestro proyecto, te invitamos a unirte al plan Master Investor. Aquí puedes aprender cómo hacerlo.
Cordialmente
El equipo de CHESS BROTHERS
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.