Handling node issues with a game on Hive Engine
Coding for blockchain is both fun and frustrating. While it offers some unique benefits to traditional programming, it also comes with a lot of unique issues you have work around.
You probably noticed today that Hive Engine was having problems, this was the result of issues with the primary Hive Engine node. This resulted in problems with numerous apps on Hive.
This caused issues with Ape Mining Club which forced it to go into catch up mode to get back to the head block. If you don't know what head block is, it is simply the latest block created on the blockchain. If your application is on any block other than the head block, it is considered to be behind.
Ape Mining Club has a lot of protections against failures, but I have not coded in node fail over yet. It was something I was planning on doing but I have not done yet, I figured I'd have more time before the main node went down again.
I want to provide this as a teaching moment for anyone else looking to make apps and games on Hive and share how I approached the issue.
When building Ape Mining Club I was fully aware of potential node issues on Hive and Hive Engine, and made certain decissions to account for it.
The first issue of course is a node not responding and going down. I'll explain how I deal with this, but for now let me talk about something I focused on first as the most critical problem to account for.
The way apps and games work that need to respond to activity on the blockchain in real-time is by fetching blocks. What this is means is a process monitors the blockchain for each new block and then processes all transactions in that block and then gets the next block. This is the core loop used by a large percentage of Hive apps.
The typical workflow is:
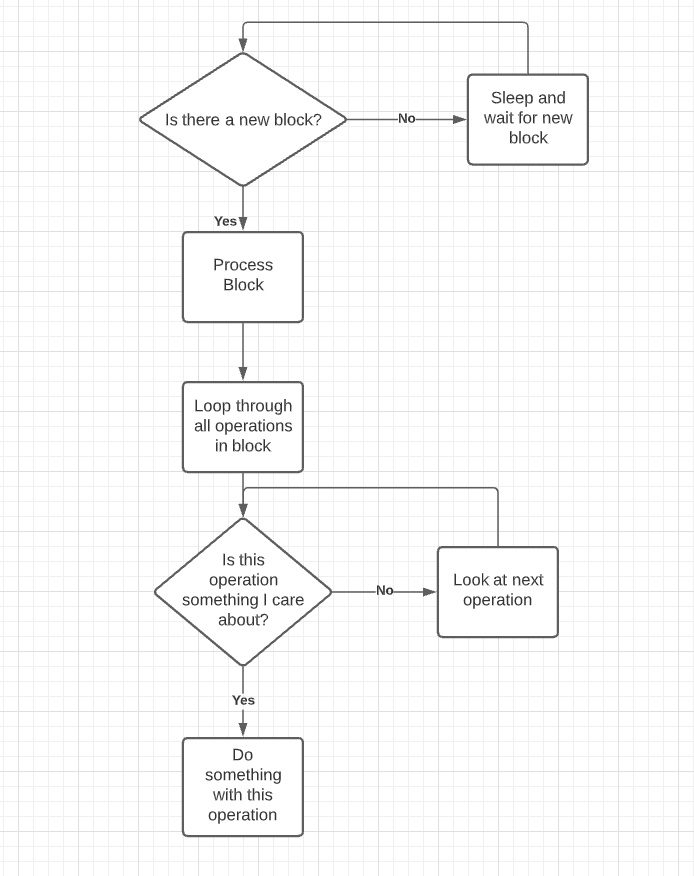
The problem with this process and one that was critical for me to address is what happens if you process some transactions in a block and then your application fails for some reason (code error, logic error, database error). You now have some transactions processed in a block but not all, do you start at the previous block and try again or do you skip this block and move on? Either option will leave you with either duplication transactions or potentially missing transactions your application cares about.
When you fetch blocks you generally will save the last block processed in a database or in a file so you know where to start from when your application has to restart. In rare cases, you don't care and you always start at the head block.
There are a ton of reasons why your application may crash and there are tons of approaches you can use to handle them.
The one I chose solves a lot of problems at once and that's ensuring each block is handled atomically. When I say atomically, I mean all at once or nothing at all. The process I use is very similar, but there are a few added steps.
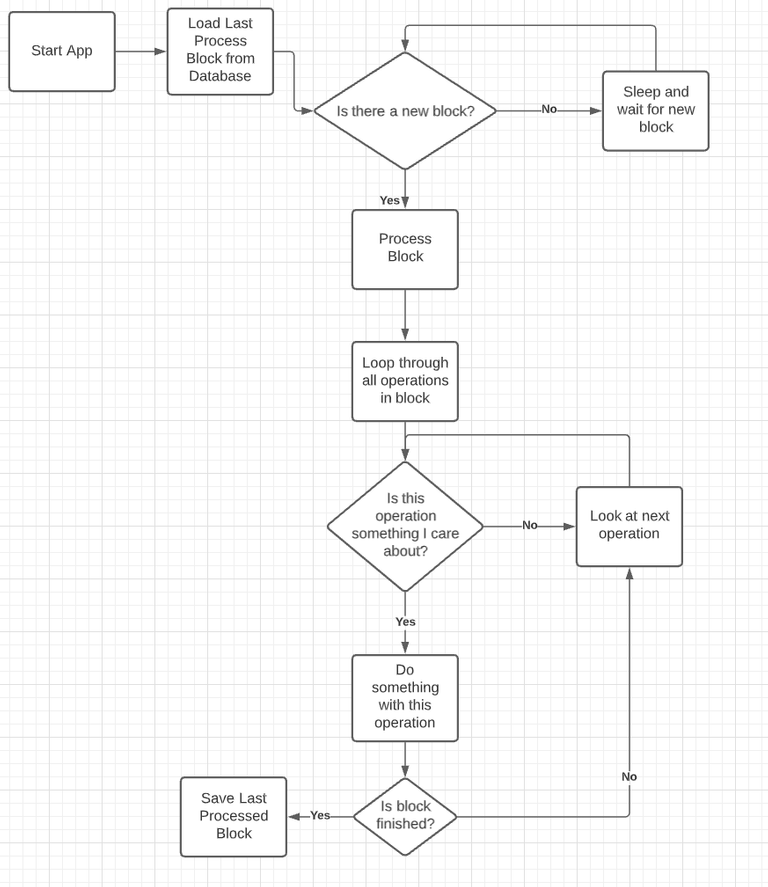
As you can see, the main difference is I load the last process block from the database and save the last processed block when the block is handled. What you don't see here is how I process the operations in these blocks.
info: -----Processing block: 9903954-----
info:
BEGIN;
call updateenginelastblock(9903954);
COMMIT;
info: -----Committing block: 9903954-----
Every block I call a stored procedure in the database to save the last processed block number. If there are game operations in the block, I process them as well.
info: -----Processing block: 9903961-----
info:
BEGIN;
call updatetokenbalance('ecoinstant', -25);
call purchaseMiner('ecoinstant', 'gpu', 25);
call updateenginelastblock(9903961);
COMMIT;
info: Processing Transfer
info: Processing Game Ops
info: -----Committing block: 9903961-----
Here you can see @ecoinstant purchased a GPU miner for 25 APE, I call a procedure to update his balance and trigger the purchaseMiner procedure (this is a very complicated procedure as many things happen here).
What you may have noticed is the BEGIN; and COMMIT; sandwiching the operations. This tells the database to handle all these operations as one transaction, so either they all complete or they all fail. If the application fails or the database fails between this operation, the application will restart and the operation will try again. It will load the last process block and move forward one block, we know we haven't done anything in this block as the transaction previously failed and nothing was saved to the database. It doesn't matter how many times I attempt to process this block, I know for sure I will only save the state to the database once. I also know no other operations can happen before it without previous ones being processed completely.
This solves the problem of avoiding duplicating transactions when the application fails, it solves the problem of properly recovering where it left off, it also solves the problem of not breaking when the nodes go down, it just falls behind.
PM2 (process manager) is used to maintain the script so if it fails it will automatically restart it. PM2 is one of the coolest utilities ever made and I highly recommend learning how to use it. While it is made for NodeJS, it works with Python, Ruby, and most everything.
While you want to do error handling if there is an error writing to the database, if the node goes down, and numerous other what ifs, this core loop prevents 98% of the problems and drastically increases the reliability of the application.
If you are running a mission critical application, you want to identify all potential issues that can cause your application to fail, but more importantly corrupt data.
This isn't the only way to solve these problems, but it is very effective. Until Hive has smart contracts, you will need a hybrid of onchain and offchain state.
There are many alternative nodes that you can use. I primarily use the below.
"heNodes": [
"https://api.hive-engine.com/rpc",
"https://herpc.dtools.dev/",
"https://herpc.neoxian.city/",
"https://herpc.kanibot.com/"
],
Alternatively you can also use
https://ha.herpc.dtools.devthat has an inbuilt failover.I personally have a script that I use in all my applications to rotate nodes when there is a failure in the current node.
I found out about this one earlier today and started using it. I want to contact @reazuliqbal sometime to ask about how it works, specifically about how the fail over as handled. I assume it's heath checks with nginx.
api2.hive-engine.com another node for your list.
Do you know where I can learn to build my own games on the blockchain?
I would first recommend getting comfortable in a programming language (typically Javascript or Python) then build soemthing, anything. You will be amazed how much more you learn by building something than you do by staying in tutorial hell.
ok recommend being software where I can build some projects easily
Well done. It's been great watching you work which provides you with added experience and knowledge of what needs to be done to address issues. Then seeing posts like this reaffirms to me why you're a witness we should all be voting for.
Block chain has great leadership. Well done and thank you for your work.
!pizza
Thank you for the good work you have been doing kudos to you
nice work I really want to learn how to make one myself but didn't find a good place to learn for free
Not sure what a food place has to do with it, but there are tons of free resources to learn any language out there.
sorry I wanted to write good place
whisper whisper you forgot to link to Ape Mining Club for those whose interest was piqued
https://apemining.club
I figured it was actually a ploy to get me to google it, increasing its searchability. Clever bastard. It worked.
Nah, I didn't want to shill it was just an informational post.
Ow!Nice work..
Wow, this seems to be too difficult but you gave it all your time. Congrats dear. keep up the good work.
Very informative! I had only learned a small amount about blockchain processing before reading this, and have learned a few more things today! It is always a great day when we learn something new!
Well said, before you begin anything you have to check the advantage and disadvantage for you to know what can cause the application to fail.
Always becareful on the type of application you are doing, always run the one you can manage easily.
Thanks for informing us.
I'm wondering if there's any mitigation being done on all Hive social apps to address duplicate content from Steemit
None really.
Cool, and glad to realize content duplication is no longer a ranking factor in this modern world. Make Hive great again 🤘
I think The HAF framework and its hive_fork_manager solve the described problems. The HAF ( hive application framework ) is a plugin for hived (hive node) and hive_fork_manager. A system that allows You and other developers to easily create SQL-based applications. The HAF ensures data consistency and drives the processing of blocks by the applications. Because SQL is the interface for the applications, HAF can be used with any language which supports SQL. The HAF is still under development, but it is worth becoming familiar with it now, since we want to release it soon
Oh thats interesting, I thought it was going to use python and be deployed like Hivemind. Thats pretty nice.