Future block chain v Sino-American entertainment wars expected
If you see my wall you will see a bunch of entries called compressed encoded binary data that basically archives websites. Not all have been completed due to going back to college last week. You will see a table that essentially either points to transactions on the block chain, or local files. You will see that some of them have multiple comments that steem either truncates on display or is a bunch of garbly-gook.
Though I don't have the mechanism to decode it online for the general public, I have effectively archived websites onto the chain and have offline tools to decode it. I can store files larger than the 64k limited by having the table point to a transaction that points to another transaction full of pointers to transactions, until it points to the data and a reader algorithmic joins them all. There are 3 images below that shows the basic idea.
1 the main post. Here we'll examine the 8th file called by this website after the maine page. This one is larger than 64kb.
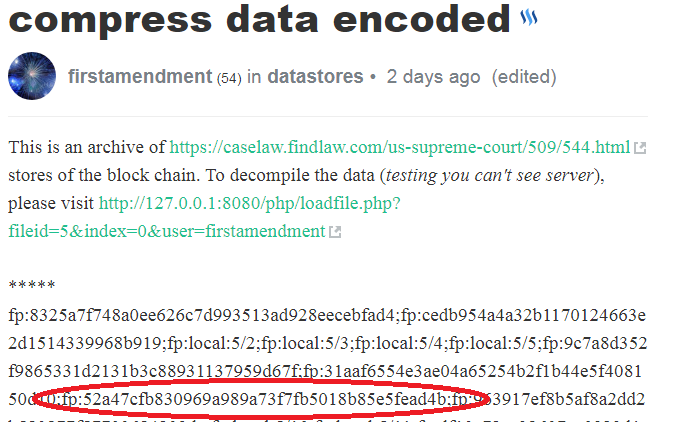
2 Here is a look up table of the 8th index. Notice it holds 3 transactions.
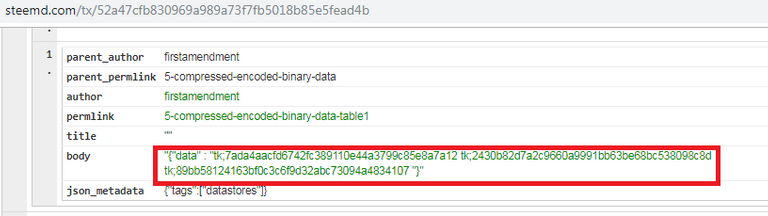
3 Here is part of the first element in the table.
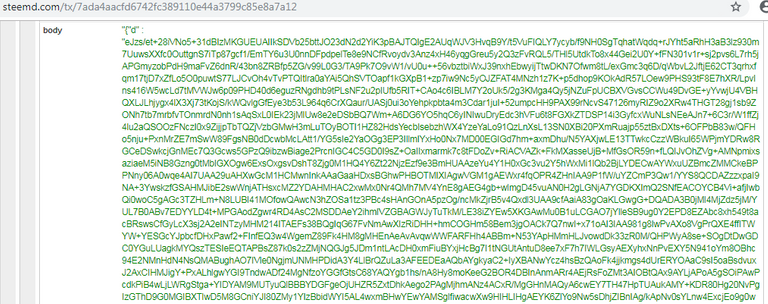
- here is a partial screen shot of retrieval on my desktop of the 8th index.
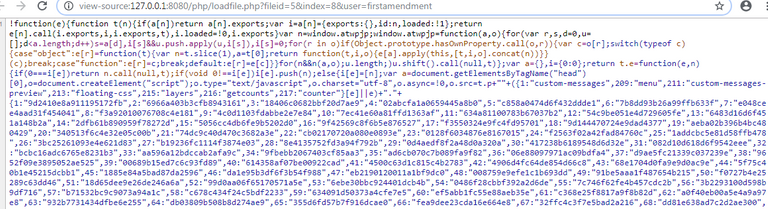
5 and here is a clip from the the project having loaded from the chain-with the media files loaded locally per project design.
Obviously there are small rooms for improvement. Why not get rid of "fp:" [or "tk;"] and just leave it as semicolon [or space] delimited. That is a fair argument which shows there is room for improvement. The concept works which is what is important, even if for larger files it could be optimized by say 10%. For our purposes, I don't think we'll store many files larger than 2MB let alone 68Mb which should be one comment's worth of transactions
directly to data. why the "d" or "data"? The "d" or "data" does help in reading the data from steemd, but there may be better methods.
Another steem user will be running this software on his server with a decoder, and I believe he will publish the source code as open source, to let other users run their own version. When the demo will start, I dunno. Open source would allow users to copy and paste the code segment to encode and decode large files on the block chain for the same or other applications-if they have that in mind.
Now having said that, 1 64k block of data is going to use up an estimated 1 steem worth of Rcs (technically 2 including the lookup table). If you want to store 1mb of data, that is going to require about 18 Steem worth of RCs. If you want a GB worth of data, well that would take a about 18k Steem RCs and beyond what I am able to test at this time. But there is bad news. In order to do this, the binary data has to be encoded to something else. A 64 Base encoding system, instead of storing 64k at a time, it is really storing up to 48k at a time. So basically multiply all the RC costs by 1.3. The good news is, some files may allow for compression.
A few megabytes can store a music file, a few more megabytes can store a music video, 2 gigabyte could store a 2 hour movie. The point that I am driving at is for 50k steem, which is still a hell of a lot of money (and likely more than 2 days to store), someone could use these basic coding principles to "permanently" store copyrighted movies on the block chain. Oh, I am sure the user would be banned if they did that, and the "permanent" store removed by hard fork. But these basic coding principles could be applied to any block chain that effectively has enough data to allow people to link transactions together and still have data left for storage.
First I want to make it clear, that the one that will ultimately host the code is storing media files locally as to make good effort take downs in compliance of copyright laws, but will store the html, css, javascript, etc to the chain. But other people who opt to run the code or parts of it on their own may opt to store everything on the chain by changing an if statement in the source code. So really nothing is sacred.
In another words, one can expect a global war on the entertainment industry. Compliance with a take down notice would have to come in the form of a hard fork, something not well tolerated by anyone-just ask our "poor" witnesses who have to stay up all night when they happen. Criminal/civil Enforcement against an individual doing the wrong could prove difficult where enforcement of copyright laws is difficult or impossible, but pretty dumb to risk violating US copy right laws if you are in a developed country. It is never wise to be the test case nor good to be a thief, but there probably will be plenty of idiots who will try and commence a battle between the Multibillion dollar Crypto market and the Multibillion dollar entertainment industry. Both are heavily influenced by the Chinese, who violate our copyrights in the first place or otherwise expect us to surrender our rights to them. Crypto is protecting our speech, while the Sino-American entertainment industry is attacking our free speech in multiple ways-including letting the audience hear what all an author has to say. It is too early to say how the battle will be resolved, but when we see Activision blizzard, and the NBA, and the lying news media screw over the American people...If such a battle forms, I would encourage people to tell their congressman to choose the block chain to punish the Entertainment industry. Oh, the democrats and the celebrities who look down at us little people will feel that one.
The harsh reality is, this little baby step of allowing large files on the chain is just ordinary progress that should have happened ages ago if coding on blockchains was better documented. Progress that ultimately cannot be stopped. Even if a chain organization puts on daily limitations (quantity of number or in data) while they are begging for onboarding, there are other chains they could use, and I am sure much of the source code of cryptos is open source and people could launch their own by copying and pasting. The Entertainment industry would be put in the position of a Don Quixote, and they will not prevail.
As far as other applications of large files. I really don't think there is much besides permanent archival purposes, or perhaps marketing purposes to say "block chain". There is, however, a chance people could use the Base 64 encoding to store/retrieve stuff from the block chain to create their own online portals to enhance what a Steemit post [or other site] could do.
As a follower of @followforupvotes this post has been randomly selected and upvoted! Enjoy your upvote and have a great day!