Your words matter , unless you are speaking to a person obviously.
Just an update on what I have learned from playing a bit more with the generative art method of CLIP+Diffusion modelling which is made simple by people far smarter than me.
I have not had a chance to play a ton, but did get to test about 4 more text prompts to instruct the AI to generate images hopefully very close to what I am picturing.
First Prompt
houses suspended over a ravine filled with galaxies. In a steampunk sci-fi style. Stained Glass Windows, Copper pipes, Mechanical.
I tried to be rather specific in this prompt, and then add what I call modifiers after the main instruction. I don't think this worked so well as you will see below. Now it could be words like "suspended" and possibly visually a "gorge", which would be a better option than "ravine".
We have to keep in mind the AI is basically googling things and concepts that seem quite simple to us might get lost in translation.


As you can see there is this general brown it likes to add in the background, I have no clue why it thinks it should be there but it could be "ravine" of stone? I only ran the 2 batches then my account ran out of free time.
Fortunately, I have a legit secondary google account, and used that to connect. They did not seem to IP block me , but possibly constantly swapping between account Google will nail me at some point.
Rendering Speed
A big thing that confused me when using the workbook and rendering was that sometimes it would take up to 3 hours for a render and then others it would only take 15minutes for the same thing.
I eventually tracked it down to what type of VM google provides you. Since on the free account resources are shared you get only 12 hours render time but also could get any one of many types of machines to render your artwork.
The one that takes extremely long is the Tesla K80, and really if you get that then it might be best to try later or refresh to hopefully get a better machine.
In your workbook you can know what type of machine you have by running only the first option setting before doing anything else.
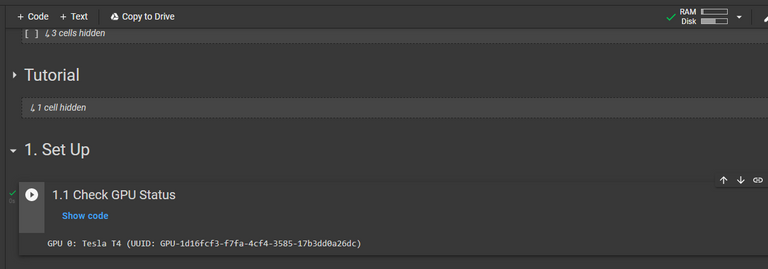
After pressing the play button in the Set Up panel, 1.1 Check GPU Status, I see that I have a Tesla T4. That is a pretty good one, and will render an image with 500 Steps in about 30minutes.
Another thing is that it is not so good at rendering people. Just a note.
Second Prompt, same style
For the second run of 2 batches, I changed the prompt up to give a bit more room but also be more specific of main elements.
Houses flaoting in a rvier made of nebula, with a planet in the background. Futuristic, Space ships, Bubbles
I kind of expected the "modifiers" I tacked on at the end to guide it a bit but this is where I see they are very influential in how it decides to render the overall image. Really it is all trial and error.


Thoughts
It even took what I can only assume is some signature, which does beg the question what is the copyright on images that kinda get style transferred but also sampled drastically to the point parts of the original may only be a single star of a specific galaxy.
The above images did turn out way better and I think it is because of the specific but also generally accessible style. Things like clouds are abundant combining that with general items can get great abstract results since there are just so many reference images available.
A good place to check these out is this imgur someone made of what you can possibly expect by using certain phrases: 200 CLIP+VQGAN keywords on 4 subjects, by kingdomakrillic
 Sourced from the above link.
Sourced from the above link.
As you see even just simple terms can make a big difference. Considering the AI is pretty dumb you do need instruct it just right and saying things like "made of vines" or "I want detail" are required if that is your intent. Instead of saying "very ornate" or maybe "viney"
For some tutorial vids you can check my previous post on this and or just google. First attempt at Generative Art
https://twitter.com/korrek_penderis/status/1500561979823505420
The rewards earned on this comment will go directly to the person sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
They look so great but it seems its not just an easy to use Program for a computer dummie like me? :-(
I also don't fiddle much with any settings since I am too scared I break things but once you get the steps down then it is rather straightforward. I will make a video running through a simple setup I think, there are a few but they kinda start with different settings which already makes it harder for beginners since we don't know those settings are not required. I think @insaneworks might be needing one also :P
!PIZZA !LUV
@penderis(2/4) gave you LUV. H-E tools | connect | <><
H-E tools | connect | <><
Tap to help.
Fine :-) will watch out for this Video! Hope it will be easy english so that I understand:-) thank you
PIZZA Holders sent $PIZZA tips in this post's comments:
penderis tipped beeber (x1)
@stickupmusic(3/5) tipped @penderis (x1)
Learn more at https://hive.pizza.
Congratulations @penderis! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 6000 comments.
Your next target is to reach 6000 replies.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Check out the last post from @hivebuzz:
Oh wow thanks for bringing this to my attention. I am always interested in new creative frontiers. Keep 'em coming!
!PIZZA
It is fun to play with, but think just as frustrating since colab will remove your connection at anytime. @insaneworks has a link to a list of AI tools available in their post for some less hassle options too. https://ecency.com/hive-177682/@insaneworks/toying-with-ai-art-and-mixing-it