Getting Activity Data From The Strava API
Welcome back. With our last article we started setting up your API Application and stored our athlete data for authenticating with Strava into a DynamoDB in Amazon Web Services. We also created our Python code to start working with the DynamoDB, and we also set up some functions to renew our access_token from Strava, after we have verified that it expires.
In this article we are going to start working with the Strava API to start getting our athletes activity data. If you need to get the back ground on this article, you can always read over our previous articles to get up to speed before we dive into this next section.
The previous two articles can be found here:
https://hive.blog/hive-163521/@strava2hive/getting-started-using-the-strava-api
https://hive.blog/hive-163521/@strava2hive/updating-your-strava-access-tokens-with-the-strava-api
In this following code, we are going to do a few different things
- We are going to connect with Strava and gather the most recent number of activities for that athlete
- Run through the activities and verify it is a Run, and then extract the information we want
1. Connect To Strava And Gather Data
We've done a little bit of work already with the Strava API, in this function we are creating below, we are calling the api/v3/athlete/activities end point. The Strava API will know exactly which athlete we need from the access token we provide as the Bearer to the request.
The full Python function we have created is listed below:
from datetime import datetime, timedelta
def access_strava_activities(athlete_access_token):
# Pass the athlete access token to strava to get activities
bearer_header = "Bearer " + str(athlete_access_token)
t = datetime.now() - timedelta(days=7)
parameters = {"after": int(t.strftime("%s"))}
headers = {'Content-Type': 'application/json', 'Authorization': bearer_header}
response = requests.get("https://www.strava.com/api/v3/athlete/activities?per_page=10", headers=headers, params=parameters)
activity_data = response.json()
return activity_data
If we start from the top, we need to add in some extra modules for Python to work with time and date a little easier:
from datetime import datetime, timedelta
The next lines, set up the name of the function and allow us to pass the athlete access_token, which is then used as part of a string variable we create called bearer_header:
def access_strava_activities(athlete_access_token):
# Pass the athlete access token to strava to get activities
bearer_header = "Bearer " + str(athlete_access_token)
The next lines set up the parameters we are going to pass to the API, specifically the time frame we want our request to be for, in this case, we are wanting the past seven days of data:
t = datetime.now() - timedelta(days=7)
parameters = {"after": int(t.strftime("%s"))}
We then set up the header of the request with the Bearer token we added earlier, and create the request to send to the API, in this case we are wanting the last 10 activities the user has added:
headers = {'Content-Type': 'application/json', 'Authorization': bearer_header}
response = requests.get("https://www.strava.com/api/v3/athlete/activities?per_page=10", headers=headers, params=parameters)
Finally the return values will be placed into a JSON format and returned back to the main body of the code:
activity_data = response.json()
return activity_data
If everything goes well, you should then get some information back from Strava, for example, the information below is one activity named "Happy Friday" and is a bike ride. We have cut off the amount of data provided, as there is a large amount of data, and we wanted to keep things a little clean in this part of our article:
[ {
"resource_state" : 2,
"athlete" : {
"id" : 134815,
"resource_state" : 1
},
"name" : "Happy Friday",
"distance" : 24931.4,
"moving_time" : 4500,
"elapsed_time" : 4500,
"total_elevation_gain" : 0,
"type" : "Ride",
"sport_type" : "MountainBikeRide",
"workout_type" : null,
"id" : 154504250376823,
Check out the API Documentation provided by Strava if you need to see some more information and you will notice that these activities only provide basic details. We can also obtain more details data on the activity from the API, including picture details and GPS details, but we will cover this off in a different article. For now if you need more details from Strava, check out the following documentation:
https://developers.strava.com/docs/reference/
2. Run Through The Activities
The output returned by the access_strava_activities function we just created, will be passed into our next function that will process all of the activities for us. In this instance, we only need a small amount of data from the information we get from Strava. This will extract the information we need, while getting ride of the rest.
The complete function, is listed below:
def process_activities(data_from_strava):
# Take the strava data and process is how you want
activities = []
for i in data_from_strava:
if i["type"] != "Run":
continue
else:
activity_vals = []
activity_vals.append(i["type"])
date_val = i["start_date_local"]
date = datetime.strptime(date_val, "%Y-%m-%dT%H:%M:%SZ")
new_date_val = date.strftime("%Y-%m-%d")
activity_vals.append(new_date_val)
activity_vals.append(i["name"])
distance = str(round(i["distance"] * .001, 2))
activity_vals.append(distance)
duration = str(round(i["moving_time"] / 60))
activity_vals.append(duration)
activity_vals.append("https://www.strava.com/activities/" + str(i["id"]))
print(activity_vals)
activities.append(activity_vals)
return activities
We can break out code into two halves. The first below sets up the name of the function and creates an array called activities, which is what we will be returning back to the main application with all the activity details in it. It also starts off a loop that will run through all the data sent to this function. The first thing it is going to do, is check the "type" value, and if it is not equal to "Run", it is going to move onto the next item.
def process_activities(data_from_strava):
# Take the strava data and process is how you want
activities = []
for i in data_from_strava:
if i["type"] != "Run":
continue
The second part of our code, will then go through the valid "Run" data and take out the information we want, including date, name, distance of the run, duration of the run and the ID value, to then be returned to the user:
else:
activity_vals = []
activity_vals.append(i["type"])
date_val = i["start_date_local"]
date = datetime.strptime(date_val, "%Y-%m-%dT%H:%M:%SZ")
new_date_val = date.strftime("%Y-%m-%d")
activity_vals.append(new_date_val)
activity_vals.append(i["name"])
distance = str(round(i["distance"] * .001, 2))
activity_vals.append(distance)
duration = str(round(i["moving_time"] / 60))
activity_vals.append(duration)
activity_vals.append("https://www.strava.com/activities/" + str(i["id"]))
print(activity_vals)
activities.append(activity_vals)
return activities
If everything goes as planned, you should then receive a list like the one below, where each line represents a different Run, and even provides the link to the Strava web page, where it is being stored:
['Run', '2023-08-18', 'Lunch Run', '4.41', '24', 'https://www.strava.com/activities/9669641521']
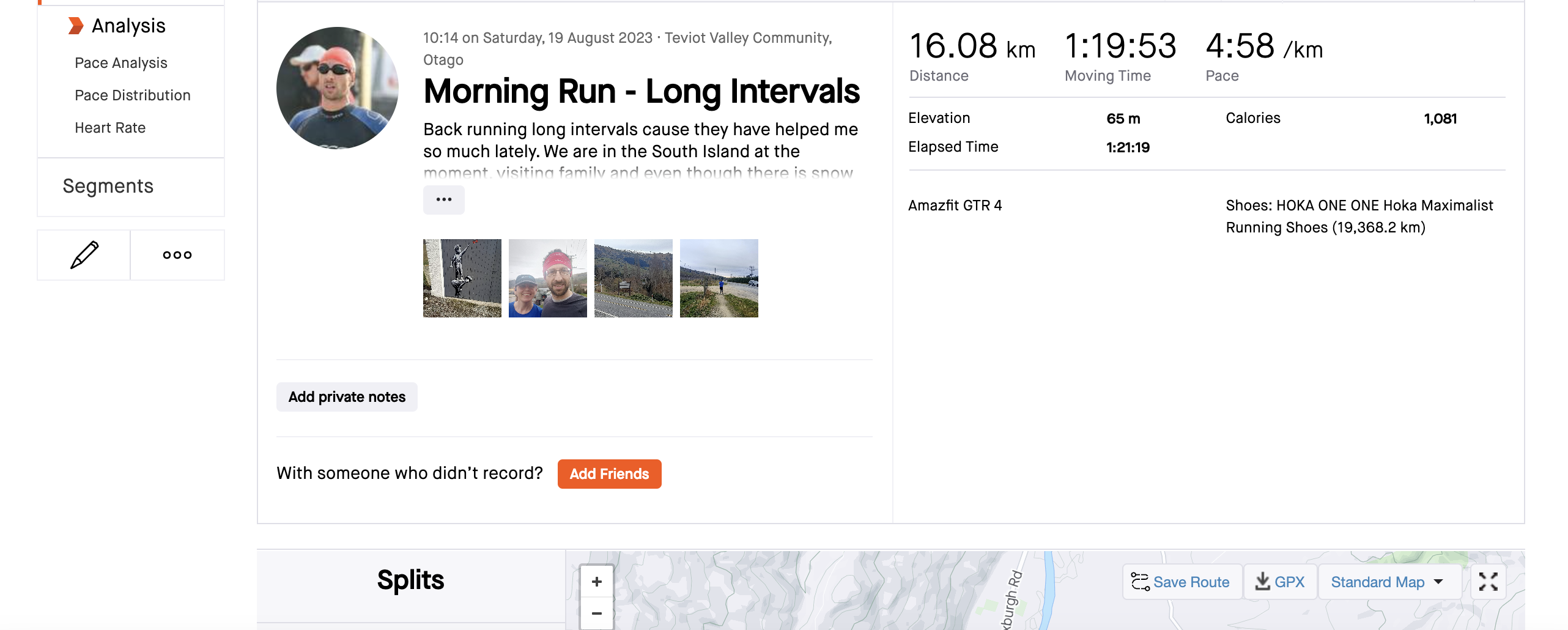
['Run', '2023-08-19', 'Morning Run - Long Intervals', '16.08', '80', 'https://www.strava.com/activities/9675578021']
['Run', '2023-08-20', 'Lunch Run', '4.08', '26', 'https://www.strava.com/activities/9682155326']
['Run', '2023-08-22', 'Morning Run Home', '7.77', '37', 'https://www.strava.com/activities/9694644165']
['Run', '2023-08-23', 'Afternoon Run', '6.37', '31', 'https://www.strava.com/activities/9703301400']
Our code is coming along pretty well, and we could move this data and store it into our DynamoDB where we have been storing our athlete authentication data. Instead, in our next article we are going to use a Google Sheet to store this information and show you how to do that. So stay tuned and let me know if you have any questions in the meantime.
Our full code is a little messy, but listed below and doing the job:
#!/usr/bin/env python
import os
import requests
import time
import re
import random
import string
import boto3
from boto3.dynamodb.conditions import Key
from datetime import datetime, timedelta
def dynamo_access():
client = boto3.client('dynamodb', region_name='ap-southeast-2', aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'), aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY'),)
dynamodb = boto3.resource('dynamodb', region_name='ap-southeast-2', aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'), aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY'),)
ddb_exceptions = client.exceptions
return dynamodb
def refresh_access_token(athlete):
# Update the strava access token every six hours
athlete_vals = athlete[0]
code_val = athlete_vals['strava_one_time']
try:
response = requests.post("https://www.strava.com/api/v3/oauth/token", params={'client_id': os.getenv('STRAVA_CLIENT_ID'), 'client_secret': os.getenv('STRAVA_SECRET'), 'code': code_val, 'grant_type': 'refresh_token', 'refresh_token': athlete_vals['strava_refresh_token']})
access_info = dict()
activity_data = response.json()
access_info['access_token'] = activity_data['access_token']
access_info['expires_at'] = activity_data['expires_at']
access_info['refresh_token'] = activity_data['refresh_token']
return access_info['access_token'], access_info['expires_at']
except:
print("Something went wrong trying to refresh the access token")
return False
def access_strava_activities(athlete_access_token):
# Pass the athlete access token to strava to get activities
#strava_access_token = athletedb_response['Items'][0]['strava_access_token']
bearer_header = "Bearer " + str(athlete_access_token)
t = datetime.now() - timedelta(days=7)
parameters = {"after": int(t.strftime("%s"))}
headers = {'Content-Type': 'application/json', 'Authorization': bearer_header}
response = requests.get("https://www.strava.com/api/v3/athlete/activities?per_page=10", headers=headers, params=parameters)
activity_data = response.json()
return activity_data
def process_activities(data_from_strava):
# Take the strava data and process is how you want
activities = []
for i in data_from_strava:
#print(i)
if i["type"] != "Run":
continue
else:
activity_vals = []
activity_vals.append(i["type"])
date_val = i["start_date_local"]
date = datetime.strptime(date_val, "%Y-%m-%dT%H:%M:%SZ")
new_date_val = date.strftime("%Y-%m-%d")
activity_vals.append(new_date_val)
activity_vals.append(i["name"])
distance = str(round(i["distance"] * .001, 2))
activity_vals.append(distance)
duration = str(round(i["moving_time"] / 60))
activity_vals.append(duration)
activity_vals.append("https://www.strava.com/activities/" + str(i["id"]))
print(activity_vals)
activities.append(activity_vals)
return activities
dynamoTable = 'ai_test_athletes'
dynamodb = dynamo_access()
print("Scanning table")
table = dynamodb.Table(dynamoTable)
athletedb_response = table.query(KeyConditionExpression=Key('athleteId').eq('1778778'))
strava_expire_date = athletedb_response['Items'][0]['strava_token_expires']
print(strava_expire_date)
expire_time = int(strava_expire_date)
current_time = time.time()
expired_value = expire_time - int(current_time)
print(expired_value)
if expired_value > 0:
print("Strava Token Still Valid")
else:
print("Strava Token Needs To Be Updated")
new_access_token, new_expire_date = refresh_access_token(athletedb_response['Items'])
print("Now we have to update the database")
print(new_access_token)
table = dynamodb.Table(dynamoTable)
athletedb_response = table.query(KeyConditionExpression=Key('athleteId').eq('1778778'))
print(athletedb_response['Items'][0])
print("Update Strava Token")
response = table.update_item(
Key={ 'athleteId': int('1778778')},
UpdateExpression='SET strava_access_token = :newStravaToken',
ExpressionAttributeValues={':newStravaToken': new_access_token},
ReturnValues="UPDATED_NEW")
response = table.update_item(Key={'athleteId': int('1778778')}, UpdateExpression='SET strava_token_expires = :newStravaExpire', ExpressionAttributeValues={':newStravaExpire': new_expire_date}, ReturnValues="UPDATED_NEW")
strava_access_token = athletedb_response['Items'][0]['strava_access_token']
ath_activities = access_strava_activities(strava_access_token)
process_activities(ath_activities)
Posted with STEMGeeks
Congratulations @strava2hive! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 90 posts.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Check out our last posts:
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.