How to Scrape Data from Web Pages Using Node.js/Express
When it comes to retrieving data from the web through scraping, not much is known about how to achieve that with Node.Js/JavaScript unlike languages like Python/PHP which already have popular modules that can help do that.
This post is going to teach you how exactly you can scrape data from the web using Node.js/JavaScript.
We are going to be using three packages to create our web scraping module so we need to install it in our Node project.
The packages are
- Cheerio
- Request
- Request Promise
After you must have set up a working Node.js server for your project, go to the project terminal and install puppeteer using this command
npm install request cheerio request-promise
Cheerio is a lean implementation of jQuery that can be used to perform front-end tasks from the back-end.
Request and request-promise are Node.js tools that will be used to make http requests.
Create a new file in the root directory of the project and name it scrape.js or something. In the file, add the following starter code as a boilerplate
const scraper = () => {
console.log('Scraping tool')
}
module.exports = scraper
In app.js which is in our project root directory, add the code
//run scraper
var scrape = require('./scrape');
scrape()
below the line
app.use('/users', usersRouter);
Save all files and rerun the server and you should get something identical to the following results in your console

In scrape.js, we are going to replace the contents of the file with the following code
const requestPromise = require('request-promise');
const url = 'https://cointelegraph.com/tags/cryptocurrencies';
const scraper = () => {
requestPromise(url)
.then(function(html){
//success!
console.log(html);
})
.catch(function(err){
//handle error
console.log(err)
});
}
module.exports = scraper
Run your server again and you should get something like this in your terminal
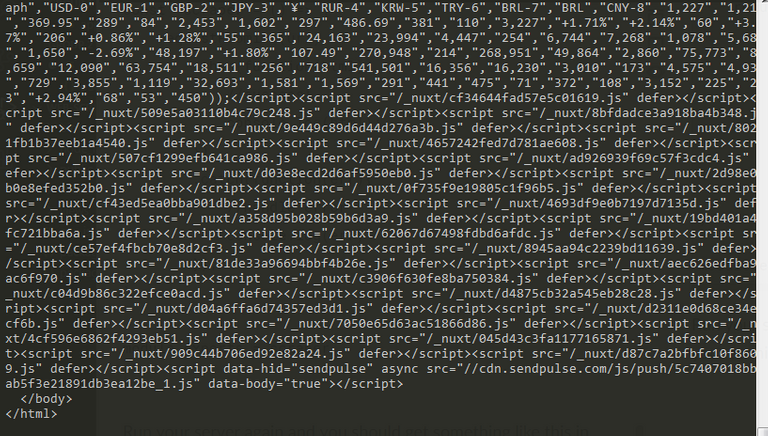
What the code above does is to use request-promise library that we installed earlier to fetch and return the html contents of any given url and log it in the console.
In this case the given url is stored in the variable url and the library is called with the keyword requestPromise, which takes the url variable as an argument and returns the HTML contents of this page https://cointelegraph.com/tags/cryptocurrencies, which is a page containing latest crypto news on the cointelegraph website.
After getiing the HTML code from the page we need to sort the code and extract whatever data we need to extract from the page.
Visit the link of the page we scraped in Chrome browser and right click on the element you want to scrape then click inspect, to get access to the element in the Chrome inspector.
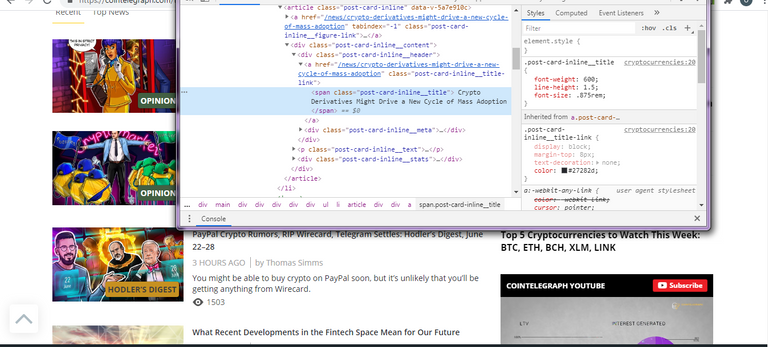
Once we are inspecting the element we want to scrape(in this case, the titles of each news piece on the page), we can now use Cheerio to parse the html for those titles and extract what we need from there.
Replace the code in scrape.js, with the following code
const requestPromise = require('request-promise');
const $ = require('cheerio');
const url = 'https://cointelegraph.com/tags/cryptocurrencies';
const scraper = () => {
requestPromise(url)
.then(function(html){
//success!
const newsHead = $('a > span.post-card-inline__title', html).toArray()
const newsTitles = []
for (let i = 0; i < newsHead.length; i++) {
newsTitles.push({
newsLink: `https://www.cointelegraph.com${newsHead[i].parent.attribs.href}`,
newsTitle: `${newsHead[i].children[0].data}`
})
}
console.log(newsTitles)
})
.catch(function(err){
//handle error
console.log(err)
});
}
module.exports = scraper
The code above takes each element that we scraped from the crypto news page and then extracts two different data which are
- Link to the actual news content
- The news title
We then store the data for each news piece in an object and the object is put into an array.
If your run server now and check the tearminal you should get a result that looks like the image below which displays an array that lists each news object
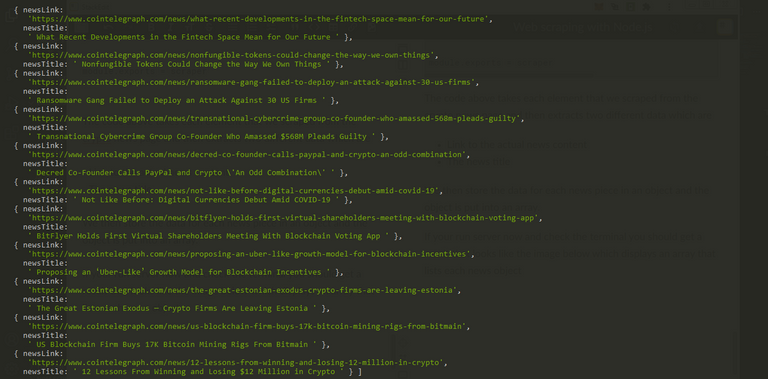
That shows us how we can successfully scrape data from a web page and use it for our own purposes on our end.
You can use this approach to get any data from any page, try it out and share your opinions in the comments.
I love javascript, even though I'm only good at Reactjs and vanilla javascript I know javascript as a 'language of all possibilities' and this tutorial proved it once again. Bookmarked!
Thanks for dropping by, glad you love the piece.
@tipu curate
Upvoted 👌 (Mana: 16/32)
Thanks for sharing an amazing Javascript tutorial. We are looking for people like you in our platform.
Your post has been submitted to be curated with @gitplait community account because this is the kind of publications we like to see in our community.
Join our Community on Hive and Chat with us on Discord.
[Gitplait-Team]
Congratulations @gotgame! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board And compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPSupport the HiveBuzz project. Vote for our proposal!