Using Python & BeautifulSoup To Obtain DJ Magazine Top 100 DJs 2021
Hi there. In this programming post, I use Python & the Beautiful Soup package to webscrape the top 100 DJs 2021 from DJ Magazine website.

{kind=link}
Topics
- About DJ Magazine Top 100 DJs
- Python & Beautiful Soup Setup
- Webscrape & Extract The Top 100 DJs
About DJ Magazine Top 100 DJs
DJ Magazine (DJ Mag) was founded in 1991 and dedicates itself to electronic dance music (EDM). Voting for the number 1 DJ was from DJ Magazine itself for the years of 1991 to 1996. Public voting started from 1997 and still continues to this day.
Trance Producer/DJ Armin van Buuren has been voted the most as #1 DJ 5 times. David Guetta, Martin Garrix & Tiësto were voted #1 3 times each.

{kind=link}
Python & Beautiful Soup Setup
The setup for BeautifulSoup in Python is not too difficult. I use jupyterNotebook for the code. The url link goes to the most recent Top 100 DJs page. At the time of writing, the url goes to the top 100 DJs for 2021.
# Imports
from bs4 import BeautifulSoup
import requests
import pandas as pd
# Imports
# URL for searching Android tablets on Newegg.ca
url = "https://djmag.com/top100djs/"
# Get Request
response = requests.get(url)
# Get the soup
soup = BeautifulSoup(response.content, 'html.parser')
Webscrape & Extract The Top 100 DJs
For this webscraping project, I wanted to extract the name of the DJ, rank change from the previous year and the interview URL. The DJ rank can be added in the dataframe in the form of range(1, 101).
When it comes to data extraction I use list comprehensions. List comprehensions in Python is nice as it is less lines of code compared to initializing empty lists and add to lists with appends in for loops.
Extract DJ Names
From the soup object, the DJ names are in the div tags with the class of top100dj-name of the HTML page. In each instance x I find the a tag and get the text to extract the DJ name. All 100 DJ names are extracted in this list comprehension.
# DJ Names are in div tags with class top100dj-name then get a tag and text.
dj_names = [x.find('a').get_text().strip() for x in soup.find_all('div', {'class': 'top100dj-name'})]
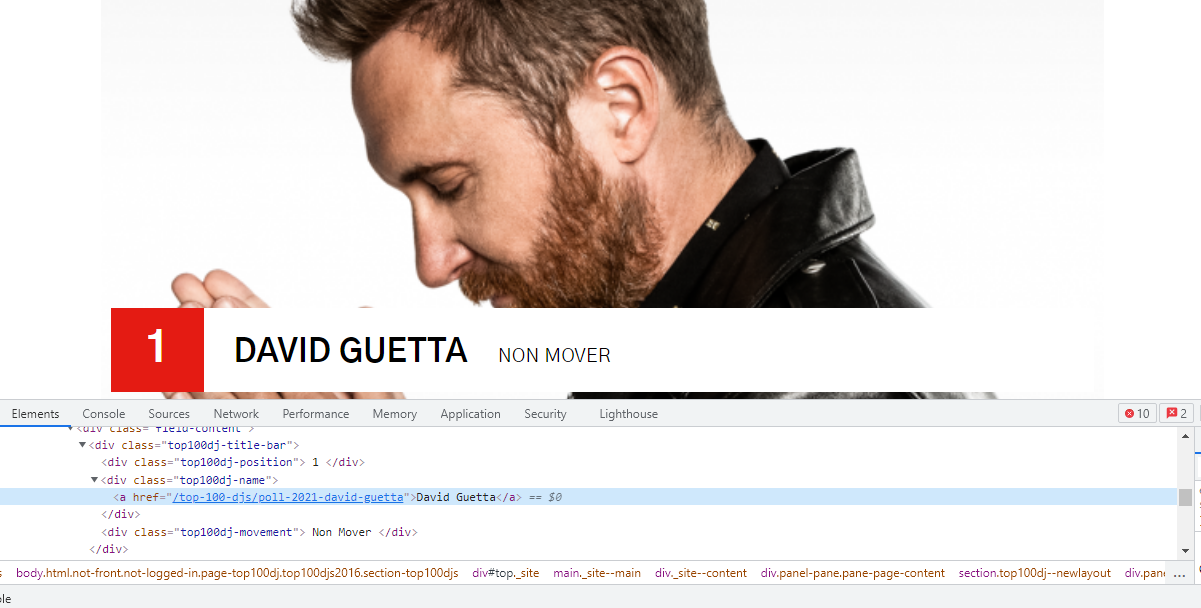
Rank Movements
Rank movements for each DJ are in the div tags associated with the class name of 'top100dj-movement'. The rank movements as text in each instance x in soup.find_all('div', {'class': 'top100dj-movement'}) are extracted.
# Rank Movements:
rank_movements = [x.get_text().strip() for x in soup.find_all('div', {'class': 'top100dj-movement'})]
![]()
Interview URLS
For the interview URLs, the hrefs do not contain the text of "https://djmag.com/top100djs/" at the start of the URL. I have to include that in before each extracted interview URL.
In each instance x, I obtain the href link from the a tag for the DJ.
# Interview URLs, adding https://djmag.com/top100djs/
interview_urls = ["https://djmag.com/top100djs/" + x.find('a')['href']
for x in soup.find_all('div', {'class': 'top100dj-name'})]
Create Dataframe
With pd.DataFrame() the pandas dataframe can be made with the extracted data.
# Create dataframe:
DJMag_top100_2021_df = pd.DataFrame({
'Rank': range(1, 101),
'DJ Name': dj_names,
'Rank Change': rank_movements,
'Interview URL': interview_urls
})
Running DJMag_top100_2021_df.head(10) gives the top 10 DJs from 2021 in the dataframe.
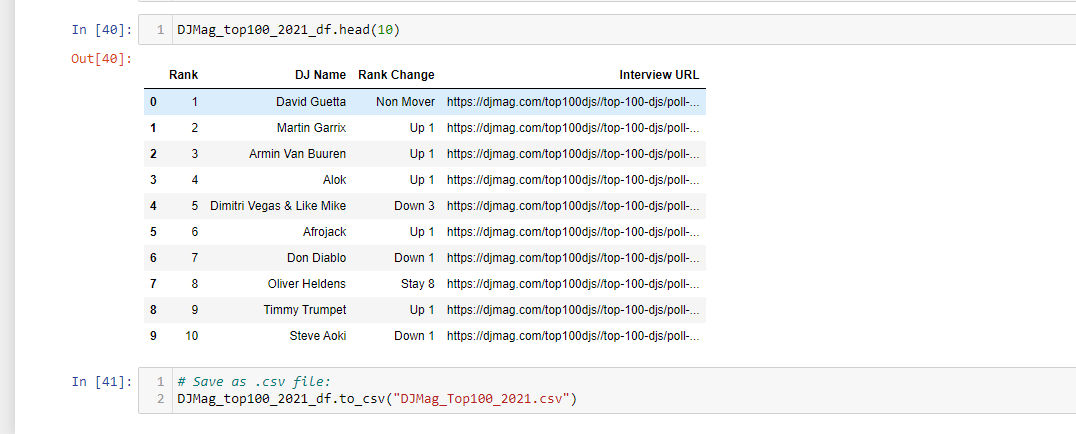
Here are the top 10 DJs from the voters for DJ Magazine in 2021 in table format.
| Rank | DJ | Rank Change | Interview URL |
|---|---|---|---|
| 1 | David Guetta | Non Mover | Interview |
| 2 | Matrin Garrix | Up 1 | Interview |
| 3 | Armin Van Buuren | Up 1 | Interview |
| 4 | Alok | Up 1 | Interview |
| 5 | Dimitri Vegas & Like Mike | Down 3 | Interview |
| 6 | Afrojack | Up 1 | Interview |
| 7 | Don Diablo | Down 1 | Interview |
| 8 | Oliver Heldens | Stay 8 | Interview |
| 9 | Timmy Trumpet | Up 1 | Interview |
| 10 | Steve Aoki | Down 1 | Interview |
Posted with STEMGeeks
Your content has been voted as a part of Encouragement program. Keep up the good work!
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more